Don't know where he gets his info, but he's sure on top of it:
https://twitter.com/ylastic
Monday, October 22, 2012
Thursday, September 6, 2012
Build Manifest Beats Artifact Registry Service
There's been a long hiatus in posting - I've been busy at a new place, finding ways to apply many of the techniques described in this blog.
One of the items I emphasized on this blog, the Artifact Registry Service, turns out to be somewhat of an overkill. In practice, the functionality overlaps with two well entrenched tools:
The basic purpose of the artifact registry service is to answer questions like these:
A Build Manifest, in a minimal form, can be a JSON file containing three items:
If a build depends on other artifacts, then those artifacts can be scanned for build manifests. Suppose the wonder-app in the example above depends on "useful-library". If that library artifact is built using the same method, it would have a build manifest of its own:
Now, to answer the questions listed above, the basic tool is to compare two build manifests, recursing through the dependency hierarchy and matching up the url/revision pairs from each build at every hierarchy level. If the urls in the manifest match up, then the VCS can be accessed and the list of commits included in one but not in the other can be computed.
A practical problem with this approach is obtaining access to the variety of VCS urls which may occur in the build manifest. Even if access permissions are granted, one often has to clone the repositories to examine the revision history, and this might become expensive when the repositories are big.
Fortunately, most companies tend to host the upstream repositories for the code they develop on a central host, so it becomes just a matter of setting up a diff service of sorts on that same host, which could just be a simple CGI script that accepts two build manifests in a PUT or POST, computes the diff between the two, accesses the VCS repositories on the local filesystem and returns a list of commits included in one but not in the other.
Now wouldn't it be wonderful if github and bitbucket had such a service?
One of the items I emphasized on this blog, the Artifact Registry Service, turns out to be somewhat of an overkill. In practice, the functionality overlaps with two well entrenched tools:
- Distributed VCS, which have well debugged and optimized methods for storing and traversing directed acyclic graphs, otherwise known as revision histories;
- Artifactory or similar artifact repository systems, combined with ivy or similar publish and retrieval tools.
The basic purpose of the artifact registry service is to answer questions like these:
- Is my fix in this build?
- What's new in the build compared to what's in production?
- What's the difference between two builds?
A Build Manifest, in a minimal form, can be a JSON file containing three items:
{ "repo": "ssh://github/someone/wonder-app.git",This JSON file is generated at build time and records the repository and changeset id used for the build. The generated file can then be included in the artifact, which is then published or otherwise reused in subsequent builds and deploys.
"rev": "1c978e4645c6b117215ea5050dc1e39c90326780",
"includes": [] }
If a build depends on other artifacts, then those artifacts can be scanned for build manifests. Suppose the wonder-app in the example above depends on "useful-library". If that library artifact is built using the same method, it would have a build manifest of its own:
{ "repo": "ssh://github/someone/useful-lib.git",Now, when building wonder-app, the build manifest can reflect this dependency by including the library build manifest in the newly generated build manifest:
"rev": "80a8d9b691febae54868835816a7bfea1968a415",
"includes": [] }
{ "repo": "ssh://github/someone/wonder-app.git",This is a very simple way of recording the complete dependency chain for a build, and can be extended to representing complete systems running a variety of concurrent services.
"rev": "1c978e4645c6b117215ea5050dc1e39c90326780",
"includes": [
{ "repo": "ssh://github/someone/useful-lib.git",
"rev": "80a8d9b691febae54868835816a7bfea1968a415",
"includes": [] } ] }
Now, to answer the questions listed above, the basic tool is to compare two build manifests, recursing through the dependency hierarchy and matching up the url/revision pairs from each build at every hierarchy level. If the urls in the manifest match up, then the VCS can be accessed and the list of commits included in one but not in the other can be computed.
A practical problem with this approach is obtaining access to the variety of VCS urls which may occur in the build manifest. Even if access permissions are granted, one often has to clone the repositories to examine the revision history, and this might become expensive when the repositories are big.
Fortunately, most companies tend to host the upstream repositories for the code they develop on a central host, so it becomes just a matter of setting up a diff service of sorts on that same host, which could just be a simple CGI script that accepts two build manifests in a PUT or POST, computes the diff between the two, accesses the VCS repositories on the local filesystem and returns a list of commits included in one but not in the other.
Now wouldn't it be wonderful if github and bitbucket had such a service?
Friday, June 29, 2012
Rewrite or Patch? Build or Buy?
These decisions are ever present when constructing larger software projects. Do you keep patching and maintaining a legacy piece of software, or do you throw it out and start over? Do you buy somebody else's code and integrate it, or do you build it yourself?
The perceived wisdom is:
Your problem is that you have no way to gauge the value of that input, and that is usually because you only have superficial insight to the problem domain.
One way to deepen your insight is to go and attempt to build it yourself. The goal of that exercise is mainly to educate yourself and gain a better understanding of the problems faced by the original creators of the legacy piece of software or of the third party library.
You go about this expecting to stop and throw your own work away once you gained enough knowledge to better understand the other products, and make a good choice. Most of the time, you will end up patching and buying, but it may very well be that your work does turn out best. More often than not, the perceived difficulty of a problem fades away, and in those cases a simple custom piece will perform better than some general purpose third party tool - but you'll only know if you try.
So don't be afraid to go and build, but don't get enamored by your work. Be honest with yourself and always compare your work with the third party work, and observe how your evaluation changes as you slowly remove obstacles and gain new insights.
All too often, people will shortcut this and buy third party software blindly - and end up disappointed and frustrated.
The perceived wisdom is:
- Throwing out and starting over is high risk
- Building yourself is high risk
Your problem is that you have no way to gauge the value of that input, and that is usually because you only have superficial insight to the problem domain.
One way to deepen your insight is to go and attempt to build it yourself. The goal of that exercise is mainly to educate yourself and gain a better understanding of the problems faced by the original creators of the legacy piece of software or of the third party library.
You go about this expecting to stop and throw your own work away once you gained enough knowledge to better understand the other products, and make a good choice. Most of the time, you will end up patching and buying, but it may very well be that your work does turn out best. More often than not, the perceived difficulty of a problem fades away, and in those cases a simple custom piece will perform better than some general purpose third party tool - but you'll only know if you try.
So don't be afraid to go and build, but don't get enamored by your work. Be honest with yourself and always compare your work with the third party work, and observe how your evaluation changes as you slowly remove obstacles and gain new insights.
All too often, people will shortcut this and buy third party software blindly - and end up disappointed and frustrated.
Tuesday, May 15, 2012
Basic Change Process Using Git
Very early on, I explained the basic change process in a diagram that's agnostic to the version control system. Git does have an interesting particularity that merits mention: the fast forward.
The motivation for this discussion came out of some questions around the promotion model, and what a "promotion" actually looks like in practice. As a reminder, a basic premise of the promotion model is that we use a stabilization branch to deploy from, and use master to aggregate all the new stuff.
One concern was that by merging master into the stabilization branch, we would create merge conflicts, and generally not be guaranteed to get the same code. If you first merge from the stabilization branch into master, then merge back, you shouldn't get that in any version control system.
With git though, you get a bonus:
 We start with a series of checkins on the main branch. In git, a branch is a linked list of revisions, the root of which is stored in the "head" of the branch, here in dark color.
We start with a series of checkins on the main branch. In git, a branch is a linked list of revisions, the root of which is stored in the "head" of the branch, here in dark color.
 When you create a new branch, you essentially create a new head, and point it to the branch point revision. The following command creates the branch and "places" you at the head of it.
When you create a new branch, you essentially create a new head, and point it to the branch point revision. The following command creates the branch and "places" you at the head of it.

Now if you check in a commit, you create a new revision. This revision will have a back pointer to the parent revision owned by the branch, and head will point to your new revision:

Meanwhile, ongoing work hasn't stopped:

Now assume you wish to "promote" master into the branch. You start by merging branch into master:

Now comes the git magic:

If you want, you can emulate that behavior in git:
The bottom line is that fast forwarding makes the two models I described in my promotion post topologically equivalent. The only thing that changes between the two models is whether you reuse the same branch name or create new branch names. Topologically, a new branch will get extruded every time you do the merge down / merge back combination, no matter what model you choose:

The motivation for this discussion came out of some questions around the promotion model, and what a "promotion" actually looks like in practice. As a reminder, a basic premise of the promotion model is that we use a stabilization branch to deploy from, and use master to aggregate all the new stuff.
One concern was that by merging master into the stabilization branch, we would create merge conflicts, and generally not be guaranteed to get the same code. If you first merge from the stabilization branch into master, then merge back, you shouldn't get that in any version control system.
With git though, you get a bonus:
We start with a series of checkins on the main branch. In git, a branch is a linked list of revisions, the root of which is stored in the "head" of the branch, here in dark color.git checkout -b branch
Now if you check in a commit, you create a new revision. This revision will have a back pointer to the parent revision owned by the branch, and head will point to your new revision:
vi somefile ...
git commit \
-a -m 'made change A'
Meanwhile, ongoing work hasn't stopped:
git checkout master
vi somefile ...
git commit -a -m 'made change B'
Now assume you wish to "promote" master into the branch. You start by merging branch into master:
git merge \
--no-commit branch
# resolve conflicts
git commit \
-a -m 'Merged branch'
Now comes the git magic:
git checkout branchNothing happens except that the head of branch is fast forwarded to the head of master. So we actually promoted the exact same revision we initially merged from the branch. Most other version control systems will create a new revision with a copy of the same content.
git merge master
If you want, you can emulate that behavior in git:
git checkout branchThis will create the copy and emulate the behavior of lesser version control systems - but why would you want to?
git merge \
--no-ff master
The bottom line is that fast forwarding makes the two models I described in my promotion post topologically equivalent. The only thing that changes between the two models is whether you reuse the same branch name or create new branch names. Topologically, a new branch will get extruded every time you do the merge down / merge back combination, no matter what model you choose:
Monday, May 14, 2012
Version Numbers Are Evil
Version numbers are a perfect example of Bikeshed. Everybody gets them, everybody will have something to say about them. Most importantly though: they hardly matter.
Some fairly famous companies like Microsoft and Apple have been seen toying around with ideas to de-emphasize them. Hence we had code names (Longhorn, Lion...) and time stamps (Windows 95), but they are truly hard to kill (IE 9)...
Unfortunately they've been around for quite some time and are ingrained in our software engineering lore.
Back in the days where you released once a year or so, or maybe once a quarter, tracking version numbers was a minor hassle, compared to the huge size of the changes and the possible impact of a new release - promptly discouraging anyone from upgrading, which in turn promptly made fixing bugs even harder: not only did you have to fix the current version, but all the "supported" ones, including perhaps some unsupported ones if the customer was important enough...
Those days are thankfully fading. Instead, we have software as a service. Ever asked what version of gmail you're using? or Facebook? doesn't make sense, does it? Not like you have a choice...
Still, version numbers haunt many of the modern build tools and dependency management tools.
I guess there is some satisfaction in exercising positive control by updating all consumers of your toolkit with the dependency to your latest version, but in practice, it's a nightmare. Not only is there a lot of error prone labor involved, but you also encourage "mix and match", and general procrastination on bugs: "Oh, the latest version breaks my app, so I'm going to stick to the older version". "Oh, the latest fixes a security hole? Well, I hope I won't get hacked"...
The smart folks who wrote the Advanced Packaging Tool (also know as aptitude, or apt-get) realized quickly that direct dependency management could not possibly function for such a complex beast as a Linux distro. They strongly discourage explicit versions in dependencies, as shown in their many examples.
The maven build system makes a very slight concession to the idea of version numbers being fluid via their -SNAPSHOT construct. It's unfortunately very inadequate, since there is no good way to relate to exactly which version was used once it was built.
Ivy fares slightly better: you can specify wildcards that will be resolved at build time. Still, you are stuck with a linear version space, when you really need a true build chain:

In most artifact repository systems, you can emulate this by creating branch or build specific channels or instances of a repository.
As a compromise, append the build number to a manually maintained version number if you must, until you realize that you never really want to change the manually maintained portion unless someone prods you...
Some fairly famous companies like Microsoft and Apple have been seen toying around with ideas to de-emphasize them. Hence we had code names (Longhorn, Lion...) and time stamps (Windows 95), but they are truly hard to kill (IE 9)...
Unfortunately they've been around for quite some time and are ingrained in our software engineering lore.
Back in the days where you released once a year or so, or maybe once a quarter, tracking version numbers was a minor hassle, compared to the huge size of the changes and the possible impact of a new release - promptly discouraging anyone from upgrading, which in turn promptly made fixing bugs even harder: not only did you have to fix the current version, but all the "supported" ones, including perhaps some unsupported ones if the customer was important enough...
Those days are thankfully fading. Instead, we have software as a service. Ever asked what version of gmail you're using? or Facebook? doesn't make sense, does it? Not like you have a choice...
Still, version numbers haunt many of the modern build tools and dependency management tools.
I guess there is some satisfaction in exercising positive control by updating all consumers of your toolkit with the dependency to your latest version, but in practice, it's a nightmare. Not only is there a lot of error prone labor involved, but you also encourage "mix and match", and general procrastination on bugs: "Oh, the latest version breaks my app, so I'm going to stick to the older version". "Oh, the latest fixes a security hole? Well, I hope I won't get hacked"...
The smart folks who wrote the Advanced Packaging Tool (also know as aptitude, or apt-get) realized quickly that direct dependency management could not possibly function for such a complex beast as a Linux distro. They strongly discourage explicit versions in dependencies, as shown in their many examples.
The maven build system makes a very slight concession to the idea of version numbers being fluid via their -SNAPSHOT construct. It's unfortunately very inadequate, since there is no good way to relate to exactly which version was used once it was built.
Ivy fares slightly better: you can specify wildcards that will be resolved at build time. Still, you are stuck with a linear version space, when you really need a true build chain:
In most artifact repository systems, you can emulate this by creating branch or build specific channels or instances of a repository.
"But are you nuts? How can you know what you built against?"You use a build number instead of a version number. The point is that it's automatically generated. You are using some continuous build system, are you? If not, get one. Jenkins is OK, TeamCity is really good, but costs money. Don't even consider testing or deploying manually built stuff.
As a compromise, append the build number to a manually maintained version number if you must, until you realize that you never really want to change the manually maintained portion unless someone prods you...
"But are you nuts? How is your app going to co-exist with my app if we depend on different base libraries?"Build assemblies - or if you're in C/C++ land, use static linking, or, if you must, package your application so that it looks up its shared libraries in a private location.
Yes, I will. It's shared for a reason. If the interface is so crummy that you cannot derive the right functionality, create a new one that is, but don't break the existing one. Modern languages have plenty of ways to extend interfaces without breaking existing code:
"But are you nuts? Are you really going to force me to make compatible changes in shared libraries?"
- Optional arguments with default values
- New methods
- Subclassing
- Traits
- ...
Wednesday, April 4, 2012
Cranky, but Good
I really want to like this guy: Ted Dziuba. A lot of good stuff there, adding to the blogroll.
Monday, March 19, 2012
Good Architecture (Part II)
I found this article by Jay Creps (blog added to the blog roll on the right) to be very interesting, and goes to the heart of whether "heighly scalabe, distributed fault tolerant systems" really are more reliable than classic monolithic systems.
Granted, if you are building a high volume site, you might have no choice, but be honest and analyze whether you really are building that high volume site. There is something to be said about software that has been in production for decades - it might not be cool, but it is certainly well tested and well known...
Granted, if you are building a high volume site, you might have no choice, but be honest and analyze whether you really are building that high volume site. There is something to be said about software that has been in production for decades - it might not be cool, but it is certainly well tested and well known...

Sunday, March 4, 2012
Slow Rate of Postings
A lot of changes are occurring in my work life, so I've been quite busy. Apologies for the long pauses, but unfortunately posting will remain erratic over the next few weeks.
Release Management Depends on Good Architecture
This is a trivial observation, one would think - but it is amazing how many systems to this day are built without any consideration on how they will be operated.
I heard rumors of a company where the developers had to carry pagers and respond to operational emergencies, enhanced by the habit of the head of operations of randomly turning off machines in the data center. This apparently did lead to developers writing more robust code so they could get some sleep.
This is a good moment to take a peek at an older Usenix paper on Crash Only Software. Anyone designing software used as a service these days really needs to read and apply these principles. There isn't any excuse in this day and age for doing anything else:
As a consequence, any new version must be fully compatible with the previous version, both in accepting incoming requests and when emitting requests. This means:
I heard rumors of a company where the developers had to carry pagers and respond to operational emergencies, enhanced by the habit of the head of operations of randomly turning off machines in the data center. This apparently did lead to developers writing more robust code so they could get some sleep.
This is a good moment to take a peek at an older Usenix paper on Crash Only Software. Anyone designing software used as a service these days really needs to read and apply these principles. There isn't any excuse in this day and age for doing anything else:
- DNS infrastructure now supports looking up hosts by service, so no client or peer service should have to be configured with explicit host names.
- Hardware load balancers will not only shape traffic, but also deal with outages.
- State and persistence is concentrated onto backend data services, where well tested redundancy and replication mechanisms exist.
An upgrade is like an outage.Simply knock out a small portion of your services, upgrade them, restart them and let the load balancer do its job.
As a consequence, any new version must be fully compatible with the previous version, both in accepting incoming requests and when emitting requests. This means:
- Modifying an API usually takes two releases: (1) Add new functionality and deploy, and only after all services are upgraded perform (2) remove obsolete functionality.
- Modifying database schemas often takes two releases: (1) add new tables and relations, and slowly start converting or moving the data - code needs to be able to deal with data in both the new and the old location, and only then (2) drop obsolete columns or tables.
Sunday, February 19, 2012
Rake - yet another reinvention of Make
So, why is Rake any better than straight old make?
I actually can think of several reasons why the rake version is superior, among them:
To compare, GNU make:require 'rake/clean' CLEAN.include('*.o') CLOBBER.include('hello') task :default => ["hello"] SRC = FileList['*.c'] OBJ = SRC.ext('o') rule '.o' => '.c' do |t| sh "cc -c -o #{t.name} #{t.source}" end file "hello" => OBJ do sh "cc -o hello #{OBJ}" end # File dependencies go here ... file 'main.o' => ['main.c', 'greet.h'] file 'greet.o' => ['greet.c']
SRC := $(wildcard *.c)
OBJ := $(patsubst %.c,%.o,$(SRC))
default: hello
clean:
rm -f *.o
clobber: clean
rm -f hello
hello: $(OBJ)
cc -o hello $(OBJ)
%.o: %.c
cc -c -o $@ $<
# File dependencies go here ...
main.o: main.c greet.h
greet.o: greet.c
I guess this is a testament to ruby that it can actually do this and make it look so close to the real thing.I actually can think of several reasons why the rake version is superior, among them:
- The ability to use a fully developed programming language instead of the GNU Make $(...) macros, some of which use very bizarre semantics
- The ability to extend it easily, by adding more ruby code.
- You do need to learn Ruby, and be comfortable with some of the Ruby contortions - but considering that Ruby appears to be the current fashion, it would probably be a good thing to learn regardless....
- In the end, you still use "sh" to invoke a shell. I really wished they addressed the shell quoting problem in a different way - I bet even after 30 years, things will fail spectacularly if any of the files have a space in them.
- It doesn't appear to me that rake really has any novel idea - in spite of there being a long history of make clones, some of which do present interesting extensions:
- Augmenting file timestamps with file hashing, in order to avoid rebuilding aggregate targets when a rebuild of an ingredient doesn't actually produce a different file...
- Extending rules to include "cascade dependencies", a way to express: "If you need X, you will also need Y". This allows you to express a C include dependency in a more direct way: "anyone who uses main.c (in the example above) will also need to depend on greet.h". This is subtly different from the classic dependencies.
Monday, February 13, 2012
Other Folks do Code Promotion Too.
This article is a related take on a promotion branching model. It appears that he does name branches using version numbers, though. It's not absolutely necessary though.

One problem common to both is that if you really need to support multiple releases of the same product in parallel on the field, you have a problem when you need to patch an older supported version.
One problem common to both is that if you really need to support multiple releases of the same product in parallel on the field, you have a problem when you need to patch an older supported version.
Saturday, February 11, 2012
Oh no! There's code too!
I've decided to revive an ancient project of mine: the autodiscovering build system. I started working on this around 1995, and used it in several companies. It's kind of sad to see it languish, as I believe it to be superior to most systems used to date (of course I would)...
For this purpose, I placed a public mercurial repo on bitbucket, at http://hg.fortified-bikesheds.com/cook-autodiscovery/.
On most UNIX boxes, it should be possible to simply clone the repository, then perform the usual
Big caveat. I'm reviving this after about a 6 year break, so some stuff is likely to break (and yes, I realize that these days, Debians are cooler than RPMs, so maybe I'll add a debian packaging module).
My goal is to get this into a presentable state again, do a little bit of refactoring to expose a better plugin architecture, and then take some big C/C++ project (firefox?) and apply it. This might take a while.
The benefits of getting this done are:
For this purpose, I placed a public mercurial repo on bitbucket, at http://hg.fortified-bikesheds.com/cook-autodiscovery/.
On most UNIX boxes, it should be possible to simply clone the repository, then perform the usual
./configureYou can then enter the examples subdirectory, and run the "b" (for build) command, installed as part of the system. This should build 4 samples, each representing a common C/C++ project scenario, and pack them up as an RPM.
make
sudo make install
Big caveat. I'm reviving this after about a 6 year break, so some stuff is likely to break (and yes, I realize that these days, Debians are cooler than RPMs, so maybe I'll add a debian packaging module).
My goal is to get this into a presentable state again, do a little bit of refactoring to expose a better plugin architecture, and then take some big C/C++ project (firefox?) and apply it. This might take a while.
The benefits of getting this done are:
- reliable parallel and incremental builds, even after source tree re-orgs;
- improved error logging by virtue of every construction step having its own log file;
- improved build debugging by having the actual build scripts for every step explicitly available;
- fine grained build configuration with exact tracing of the origins of every setting;
- simplicity for the developer: "drop code here".
- No IDE support - it's conceivable to add a project file generator to this, or leverage existing project file generators. Of course, once you add a project file generator, the benefits of the incremental builds go away...
- Modern C/C++ toolchains tend to choke over the link step, rendering the benefit of incremental parallel builds less interesting
- Expects a "traditional" large source tree. In other posts, I've been arguing that many small source trees, each generating archives or artifacts might be a better way to go.
Friday, February 10, 2012
Building an Artifact Registry Service (part 2)
In a previous post, I explained how to map changeset ids to a monotonically increasing build number. The basic motivation for this was to create an entity which was usable as a version number, but mapped to a unique source code configuration.
In this post, I'll build on this foundation and show how we can incrementally add changeset information as metadata attached to the build number.
 Let's start with a single repo "A", and attach it to some sort of continuous build system.
Let's start with a single repo "A", and attach it to some sort of continuous build system.
It will see checkin Nr. 101, and produce build Nr. 1. We will associate checkin Nr. 101 to the build Nr. 1, saying "Build Nr 1 includes change Nr. 101".
Sometime later, checkin Nr. 102 occurs, and it will trigger build Nr. 2. Now, we associate change Nr. 102 to build Nr. 2, and then look at Nr. 102's ancestor, and notice that it has been built by build Nr 1. Now instead of including change Nr. 101, we will associate the build Nr. 1 to build Nr. 2, saying "Build Nr 2 includes build Nr. 1". The idea is that we can stop scanning for further changes at that point, since the previous build already includes all of them.
See how it works when three quick checkins happen in a row, and only at checkin Nr. 105 does the continuous build system kick in and produce build Nr. 3. Now our scan picks up changes Nr 103, 104 and 105 and includes them in build Nr. 3, but then notices that change Nr 102 is in build Nr 2, so it includes that in build Nr 3, and stops the scan.
The real kicker of this method is that we can re-use the "build includes build" relationship to express dependencies to other builds.
 For example here: builds done in repo A use an artifact generated in builds done in Repo B. Say we have configured our continuous build system to kick off a build in repo A whenever a build in repo B finishes.
For example here: builds done in repo A use an artifact generated in builds done in Repo B. Say we have configured our continuous build system to kick off a build in repo A whenever a build in repo B finishes.
So while developers furiously check in changes, builds keep coming, and every time a build on repo A happens, it uses the latest build from repo B to build the final artifact from repo A. It behooves us to add the relationship that build Nr. 5 includes not only build Nr. 3 but also build Nr 4 from the other repository.
Now if we want to know what the difference between build Nr. 3 and build Nr. 5 is, we can simply start by following all the arrows from build Nr. 3 and cross off all the places we traverse, which would be builds Nr. 1 and 2 and changes Nr. 101, 102 and 201. Then we start at build Nr. 5 and start following arrows until we hit something we've already seen: This would be build Nr. 4 and changes Nr 103, 104, 105 and 202 and 203.
 Now let's assume nothing happens in repo A, but two more changes get put into repo B. This produces build Nr 6, which then kicks off a build on repo A.
Now let's assume nothing happens in repo A, but two more changes get put into repo B. This produces build Nr 6, which then kicks off a build on repo A.
This should create a build Nr 7, as shown. It is distinct from the previous build, as it uses a new artifact built on repo B, so a rebuild must occur even though nothing changed in repo A.
This shows that once we use dependent builds like this, we cannot simply map the changeset id (i.e. the number 105) to a build number, but we must use a hash composed of the changeset id of the repo where the build is occurring and all the build numbers the build depends on. In this case we would use "Changeset 105" + "Build 4" to create the hash that maps to build Nr. 5, and subsequently "Changeset 105" + "Build 6" to map to build Nr 7.
Nothing changes in our "Find the delta between two builds" algorithm described above, it will correctly determine that the difference between build Nr. 5 and Nr. 7 are the changesets 204 and 205.
The beauty of this method is that it scales naturally to complex dependency graphs, and will allow mixing and matching of arbitrary builds from arbitrary repositories, as long as a unique identifier can be used to correctly locate the changeset used in the build in every repository.
In part 3, I'll be talking about additional metadata which we may wish to include in our artifact repository service, and how that service can become the cornerstone of your release management organization.
In this post, I'll build on this foundation and show how we can incrementally add changeset information as metadata attached to the build number.

It will see checkin Nr. 101, and produce build Nr. 1. We will associate checkin Nr. 101 to the build Nr. 1, saying "Build Nr 1 includes change Nr. 101".
Sometime later, checkin Nr. 102 occurs, and it will trigger build Nr. 2. Now, we associate change Nr. 102 to build Nr. 2, and then look at Nr. 102's ancestor, and notice that it has been built by build Nr 1. Now instead of including change Nr. 101, we will associate the build Nr. 1 to build Nr. 2, saying "Build Nr 2 includes build Nr. 1". The idea is that we can stop scanning for further changes at that point, since the previous build already includes all of them.
See how it works when three quick checkins happen in a row, and only at checkin Nr. 105 does the continuous build system kick in and produce build Nr. 3. Now our scan picks up changes Nr 103, 104 and 105 and includes them in build Nr. 3, but then notices that change Nr 102 is in build Nr 2, so it includes that in build Nr 3, and stops the scan.
The real kicker of this method is that we can re-use the "build includes build" relationship to express dependencies to other builds.

So while developers furiously check in changes, builds keep coming, and every time a build on repo A happens, it uses the latest build from repo B to build the final artifact from repo A. It behooves us to add the relationship that build Nr. 5 includes not only build Nr. 3 but also build Nr 4 from the other repository.
Now if we want to know what the difference between build Nr. 3 and build Nr. 5 is, we can simply start by following all the arrows from build Nr. 3 and cross off all the places we traverse, which would be builds Nr. 1 and 2 and changes Nr. 101, 102 and 201. Then we start at build Nr. 5 and start following arrows until we hit something we've already seen: This would be build Nr. 4 and changes Nr 103, 104, 105 and 202 and 203.

This should create a build Nr 7, as shown. It is distinct from the previous build, as it uses a new artifact built on repo B, so a rebuild must occur even though nothing changed in repo A.
This shows that once we use dependent builds like this, we cannot simply map the changeset id (i.e. the number 105) to a build number, but we must use a hash composed of the changeset id of the repo where the build is occurring and all the build numbers the build depends on. In this case we would use "Changeset 105" + "Build 4" to create the hash that maps to build Nr. 5, and subsequently "Changeset 105" + "Build 6" to map to build Nr 7.
Nothing changes in our "Find the delta between two builds" algorithm described above, it will correctly determine that the difference between build Nr. 5 and Nr. 7 are the changesets 204 and 205.
The beauty of this method is that it scales naturally to complex dependency graphs, and will allow mixing and matching of arbitrary builds from arbitrary repositories, as long as a unique identifier can be used to correctly locate the changeset used in the build in every repository.
In part 3, I'll be talking about additional metadata which we may wish to include in our artifact repository service, and how that service can become the cornerstone of your release management organization.
Thursday, February 9, 2012
Update of the Autodetecting Build System Demo
I recently wanted to show off my automated dependency generating build system and I noticed that the rpmbuild semantics have subtly changed in the past 6 years, so I uploaded a new version with a fix.
Check it out... I know that these days C/C++ based build systems are uncool, but just in case - I still think that in spite (or rather because of) its age, this demo has value:
Check it out... I know that these days C/C++ based build systems are uncool, but just in case - I still think that in spite (or rather because of) its age, this demo has value:
- It shows how to incrementally regenerate dependencies, leading to reliable incremental builds, even after refactorings;
- It shows how you can get a handle on build logs;
- It's a great framework for managing build configurations
- It works well with parallel builds.
Saturday, February 4, 2012
The Seven Deadly Sins of Build Systems
Build systems tend to be among the messiest code around. Arguably, many many coding sins are being perpetrated there, so it's kind of hard to pare it down to seven.
I do think the following are the most common, and also the simplest to fix.
1. Changing Files In Place
As far as sins go, this one is rather minor. There may even be some good reasons to do this, but in most cases where I've seen it happen, it was due to a reluctance to admit that there actually is a proper, full scale code generation problem at hand.
This sin is fortunately getting rarer, as people are adopting saner version control systems like mercurial or git. Nevertheless, it is still common that a build system will either access multiple branches of the source tree at the same time, or even perform checkouts.
Remedy is to collect your sources prior to starting the build.
If you are using a version control system that conflates branches with source trees (e.g. perforce and subversion), don't let branches appear in the source tree. Use the version control system to prepare your source tree from the right branches for you and only then let the build system loose.
3. Build Systems Performing Version Control Checkins
Unfortunately very common. Most common is abusing the version control system to perform duties that should be performed by a different service, for example an artifact repository (to store built binaries) or registry system (to store generated configurations or logs). If you do this, the obvious next question becomes how you would resolve merge conflicts stemming from those checkins. Assume they never happen?
4. Mixing up Build Configuration with Runtime Configuration
This is very common. This likely stems from the way most open source software is packaged and deployed:
The important thing people miss is that this is a packaging and installation model, not a development model - and as a distribution model it might not even be good for you, as many shops wouldn't dream of shipping their sources and expecting their customers to build it locally.
Unfortunately, the lore has won, and many build systems continue to be modeled like open source packages, with two main effects:
5. Mixing up Build with Packaging and with Deploy
This is mostly just sloppy coding. At this day and age, it shouldn't require convincing that encapsulation, separation of concerns and clean APIs are good things. When designing build systems, it is helpful to consider a couple of little disaster scenarios:
6. Builds Spill Outside Their Designated Area

Otherwise known as "works on my machine". Three sources of evil:
7. Labeling Builds
This one epitomizes the strong belief in rituals often found in build engineering. All version control systems have ways to identify a unique source code configuration. If they didn't, they wouldn't be source code control systems. It is sufficient to register the parameters required to recreate the source code configuration. You need some sort of registry no matter what you do - and using labels for that job can actually be a lot more complicated than one might think at first:
In the end, you will be producing many thousands of builds each year, and the vast majority of them are useless, never to be referenced again. Keeping track of all those labels can be quite a burden.
Instead: label the important builds, after you know that they really are important (e.g. when the products built from those sources are released). Then the presence of a label actually means something, and may help answer questions like "Where did you want me to clone from?".
I do think the following are the most common, and also the simplest to fix.
1. Changing Files In Place
As far as sins go, this one is rather minor. There may even be some good reasons to do this, but in most cases where I've seen it happen, it was due to a reluctance to admit that there actually is a proper, full scale code generation problem at hand.
Best is to avoid doing it: rename the file, for example by appending a .in or a .template suffix, and generate the target file via the build system.
Situations where this may be inconvenient are rare, but do exist. For example if the generation step is not useful for developers, developers might want a way to skip it - especially if the code generation is to generate files used in an IDE. Better of course would be to teach the IDE how to generate the files themselves, but that may be impractical in some cases.
If you must do it:
- ensure your modification is "idem-potent", i.e. it doesn't care if has been run before
- ensure it's OK for the modified files to be checked in as such.
This sin is fortunately getting rarer, as people are adopting saner version control systems like mercurial or git. Nevertheless, it is still common that a build system will either access multiple branches of the source tree at the same time, or even perform checkouts.
Remedy is to collect your sources prior to starting the build.
If you are using a version control system that conflates branches with source trees (e.g. perforce and subversion), don't let branches appear in the source tree. Use the version control system to prepare your source tree from the right branches for you and only then let the build system loose.
3. Build Systems Performing Version Control Checkins
Unfortunately very common. Most common is abusing the version control system to perform duties that should be performed by a different service, for example an artifact repository (to store built binaries) or registry system (to store generated configurations or logs). If you do this, the obvious next question becomes how you would resolve merge conflicts stemming from those checkins. Assume they never happen?
4. Mixing up Build Configuration with Runtime Configuration
This is very common. This likely stems from the way most open source software is packaged and deployed:
- Unpack source
- configure
- make install
The important thing people miss is that this is a packaging and installation model, not a development model - and as a distribution model it might not even be good for you, as many shops wouldn't dream of shipping their sources and expecting their customers to build it locally.
Unfortunately, the lore has won, and many build systems continue to be modeled like open source packages, with two main effects:
- Your build system spends a lot of time moving files around, aka installing them (where?)
- Any change in the runtime environment (install location, names of other services, host names etc) requires a rebuild
5. Mixing up Build with Packaging and with Deploy
This is mostly just sloppy coding. At this day and age, it shouldn't require convincing that encapsulation, separation of concerns and clean APIs are good things. When designing build systems, it is helpful to consider a couple of little disaster scenarios:
- Pretend you must change your version control system, now!
- Pretend you must switch to a different packaging system, now of course!
- Pretend your switching deploy strategies (e.g. from an incremental update to wholesale re-imaging)
6. Builds Spill Outside Their Designated Area
Otherwise known as "works on my machine". Three sources of evil:
- Uncatalogued dependencies on outside files
- Undocumented and unvalidated dependencies on the environment
- Writing to locations shared by others
7. Labeling Builds
This one epitomizes the strong belief in rituals often found in build engineering. All version control systems have ways to identify a unique source code configuration. If they didn't, they wouldn't be source code control systems. It is sufficient to register the parameters required to recreate the source code configuration. You need some sort of registry no matter what you do - and using labels for that job can actually be a lot more complicated than one might think at first:
- You need to generate a label name. The complication here is about what to do when multiple builds are done at the same time, using the same source code configuration (e.g. multi-platform builds): use the same label? use multiple labels?
- You need to ensure the labeling completes. In some systems, labeling is not an atomic operation. Instead, every file is labeled individually.
In the end, you will be producing many thousands of builds each year, and the vast majority of them are useless, never to be referenced again. Keeping track of all those labels can be quite a burden.
Instead: label the important builds, after you know that they really are important (e.g. when the products built from those sources are released). Then the presence of a label actually means something, and may help answer questions like "Where did you want me to clone from?".
Thursday, February 2, 2012
Git Cheatsheet
Pretty nice work: http://www.ndpsoftware.com/git-cheatsheet.html
So is this: http://opinionatedprogrammer.com/2011/01/colorful-bash-prompt-reflecting-git-status/
... and while we're on a roll, check this out: https://github.com/robbyrussell/oh-my-zsh
So is this: http://opinionatedprogrammer.com/2011/01/colorful-bash-prompt-reflecting-git-status/
... and while we're on a roll, check this out: https://github.com/robbyrussell/oh-my-zsh
Monday, January 23, 2012
More on Branch Promotion
One important and non-obvious trick of the trade when implementing a branch promotion model is to only promote to your production branch after committing to the deploy or release of the product. Ideally, you promote once you know you will not be rolling back, which could be as late as a week or two after the actual release!
Doing this ensures that while you are certifying your release candidate, you can still perform emergency production patches and not lose them.
In order to do this, it is important to ensure your builds do not depend somehow on the intended deploy target, because you would want to be able to deploy any build no matter where it was made. Doing this ensures that your build artifacts are properly reusable, and no unneeded rebuilds take place.
Doing this ensures that while you are certifying your release candidate, you can still perform emergency production patches and not lose them.
In order to do this, it is important to ensure your builds do not depend somehow on the intended deploy target, because you would want to be able to deploy any build no matter where it was made. Doing this ensures that your build artifacts are properly reusable, and no unneeded rebuilds take place.
Saturday, January 21, 2012
Building an Artifact Registry Service (Part 1)
In previous posts, I made the point that builds are precious. Managing the artifacts produced by those builds is a problem that is very similar to source control. In fact, it's so similar that many shops will store build artifacts in the same version control system used for the source itself.
Storing large blobs of binary data in a revision control system has the advantage of simplicity, but also many drawbacks:
Going down the road of having a build system modify source code is a dangerous path. You will need to address the question of how to resolve the inevitable merge conflicts that arise when multiple branches and builds are happening at the same time.
A better way to proceed is to examine how packaging systems resolve these problems. Packaging systems will rarely reference a specific package by version. Usually, the reference is of the form: "I need package X" or "I need at least version 1.3 of package Y". These dependency references need to be edited only rarely, and usually in conjunction with a code change that affects those requirements - and those are perfectly good reasons to edit a source file and cause merge trouble for others.
Packaging systems will then attempt to resolve the dependencies using all the repositories it knows about. This is very similar, btw, to the way most linkers resolve dependencies. You have two components:
So, to recap:
Building a service to do that part is quite simple, as all revision control systems have some method for identifying a source code state:
With a simple service like this, you can already achieve a lot of things. Most importantly, that number can be used to index into an artifact repository, and since that number is monotonically increasing, it is simple to get the latest build of an artifact.
But, as we will see, once we have this service, it becomes the natural storage location for much of the metadata associated with a build:
Storing large blobs of binary data in a revision control system has the advantage of simplicity, but also many drawbacks:
- Revision control systems are optimized for text files and provide features to efficiently diff and merge them. All that machinery is useless for binary blobs.
- Most revision control systems rely on changeset deltas to efficiently store multiple revisions. This doesn't work well for binary blobs, so your storage requirements for your repository goes way up.
- Checking out a local copy of the source tree will retrieve all the binary blobs you could perhaps need, but probably won't need. Due to the time it takes to download all those blobs, people will be reluctant to create multiple checkouts as needed, encouraging the bad practice of developing multiple independent changes in the same workspace. It also encourages use of incremental builds for continuous integration, which poses significant challenges for the build system.
"Version the reference, not the blob."Once you start doing that, another problem crops up: the references change often. If you store the reference in a source file, you will find yourself editing that file very often, or maybe even having the build system edit the file and check it in. Unfortunately, this practice is very common, as various build systems like ant pride themselves in having built-in features to support it.
Going down the road of having a build system modify source code is a dangerous path. You will need to address the question of how to resolve the inevitable merge conflicts that arise when multiple branches and builds are happening at the same time.
A better way to proceed is to examine how packaging systems resolve these problems. Packaging systems will rarely reference a specific package by version. Usually, the reference is of the form: "I need package X" or "I need at least version 1.3 of package Y". These dependency references need to be edited only rarely, and usually in conjunction with a code change that affects those requirements - and those are perfectly good reasons to edit a source file and cause merge trouble for others.
Packaging systems will then attempt to resolve the dependencies using all the repositories it knows about. This is very similar, btw, to the way most linkers resolve dependencies. You have two components:
- What you need (think -l flag);
- Where to find it (think -L flag).
So, to recap:
- Checking in binary blobs in revision control systems is bad;
- Checking in explicit references into source files is slightly better, but still bad if those references change often (as they will in a live software development project)
- Checking in references as requirements and using a system to resolve those requirements using a source of knowledge of what is available is good.
- A set of artifact repositories
- A registry service or indexing service to help you locate the right artifact for your build and track exactly what the artifact consists of.
- It must map to a specific feature set (i.e. source code state)
- It must increase monotonically over time (i.e. a higher number means a newer version)
major.minor.patch.buildnr
The trick is to let humans worry about the major.minor.patch bikeshed,
but let the build number be generated automatically. As long as the
build number by itself fulfills our two conditions above, we're good.
Building a service to do that part is quite simple, as all revision control systems have some method for identifying a source code state:
- svn and perforce have changeset numbers that already display good monotonic behavior;
- git and mercurial have changeset hashes, which would need to be converted to numbers by our registry service;
- Any system will at minimum have a unique id for every file revision, and a changeset can be defined as the hash constructed from the sorted list of all the file revisions touched by that change. Pass that hash to the registry service and obtain the number.
http://<someplace.com>/ars/changeset/<hash>returning a number, either the number already assigned to the given hash, or a new number if that hash is not known to the system, and:
http://<someplace.com>/ars/build/<nr>delivering back the hash associated with the build.
With a simple service like this, you can already achieve a lot of things. Most importantly, that number can be used to index into an artifact repository, and since that number is monotonically increasing, it is simple to get the latest build of an artifact.
But, as we will see, once we have this service, it becomes the natural storage location for much of the metadata associated with a build:
- artifact name
- artifact repository location(s)
- platforms and variants built
- changesets included in that build
- dependencies included in that build
- source code repository location(s) used in the build
- ...
Thursday, January 12, 2012
Versions in Branch Names Considered Harmful
Several bikesheds for the price of one here. I'll skip the bikeshed on how to actually generate version numbers and just explain why you shouldn't use version numbers in branch names.
A common release branching strategy looks like this:
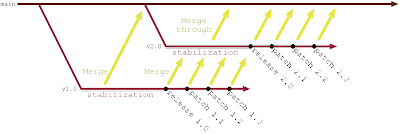
The idea is that when you have a conflict between work required for the current release and work for the next release, you create a release branch. Whatever the timing of the branch creation is, there is a temptation to create a new branch for every release.
There are some trade-offs in doing this:
Instead, I advocate for role based branching. We observe that the release branches really serve two roles: stabilization and patching. So instead of performing these activities on the same branch, we copy (promote) the code from one branch to the next until we end up in the production (or hotfix) branch, where patches can be applied:
The tradeoffs here are different:
To Summarize:
A common release branching strategy looks like this:

The idea is that when you have a conflict between work required for the current release and work for the next release, you create a release branch. Whatever the timing of the branch creation is, there is a temptation to create a new branch for every release.
There are some trade-offs in doing this:
- You do know where you're at, so that's good;
- If you need to support many older releases at the same time, it is easy to out the right place to patch;
- You need to track what the "current" branch is, especially if you wish to use automated deploys;
- You need to actively verify whether the merges back into your mainline have been performed.
- You could, in theory, work on stabilizing multiple releases concurrently.
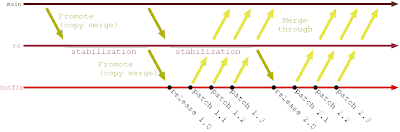
Instead, I advocate for role based branching. We observe that the release branches really serve two roles: stabilization and patching. So instead of performing these activities on the same branch, we copy (promote) the code from one branch to the next until we end up in the production (or hotfix) branch, where patches can be applied:

The tradeoffs here are different:
- You can only work on one stabilization at a time ;
- Patching the latest release is easy, but patching older releases is more complicated, as you need to create an ad-hoc branch at that release, patch there, then merge through;
- You always know where your current release branch and your current patch (hotfix) branch is;
- Configuring automated deploys to test environments is easy, as the source locations are constant;
- If the merge through steps have been omitted, you find out when you try to promote, as this merge will no longer be a copy merge.
- The total number of branches known to your version control system is reduced.
To Summarize:
- Use branches to reflect the role or the state of the code contained in the branch;
- Use labels to reflect versions;
- Merge stable code into unstable code and resolve in the unstable branches;
- Ensure that promotions are true copy merges.
Tuesday, January 10, 2012
The Strange Aversion Against Shells
I keep running into code that looks like this:
Yeah, so shells are 30 years old or more - and that's a problem, because? At least they're stable and ubiquitous. On Windows? Get CygWin - yeah, not perfect, but then again, you're on Windows, right?
It gets worse: people hate on old tools like GNU Make, only to create ant. Really? A dependency management language in XML where the execution portion is in java?
If I need a custom action and use Make, I write the rule and the dependencies, and then I write a <gasp> shell script indented by (oh noes) tabs. Done.
If I need a custom action in ant, I need a java IDE, a java build system (probably ant - with fun bootstrapping issues to go along), a deploy strategy to ensure that ant actually uses my plugin, and I still end up writing code looking strangely like shell scripts....
To be cool, I should precede that with exhaustive research on whether there already isn't a plugin that sort of kind of does what I need and think about whether I can live with the 80% solution when I can just write my 100% solution in as few as 3-4 lines of shell.
Of course shells aren't perfect - but for build tasks they are really good. They handle environments (which, btw, have both encapsulation and inheritance), I/O, subprocesses and file system manipulations with ease. If you do have complex data structures, nothing prevents you to write helper scripts to deal with them, or go the other way around and write shell script generators and at least be honest about it instead of hiding them behind system() or popen() calls.
Build systems would be so much simpler if people accepted shell as a valid tool instead of treating it like some embarrassing relative.
$command = "utility arg1 arg2";or worse:
FH = open("$command |");
while (<FH>) {
if /regexp/ ....
args = []Why are people so averse to actually writing shell scripts instead of embedding shell scripts into other scripting languages?
if opt.long: args.append("-l")
if opt.quiet: args.append("-q")
...
system(command, args)
Yeah, so shells are 30 years old or more - and that's a problem, because? At least they're stable and ubiquitous. On Windows? Get CygWin - yeah, not perfect, but then again, you're on Windows, right?
It gets worse: people hate on old tools like GNU Make, only to create ant. Really? A dependency management language in XML where the execution portion is in java?
If I need a custom action and use Make, I write the rule and the dependencies, and then I write a <gasp> shell script indented by (oh noes) tabs. Done.
If I need a custom action in ant, I need a java IDE, a java build system (probably ant - with fun bootstrapping issues to go along), a deploy strategy to ensure that ant actually uses my plugin, and I still end up writing code looking strangely like shell scripts....
To be cool, I should precede that with exhaustive research on whether there already isn't a plugin that sort of kind of does what I need and think about whether I can live with the 80% solution when I can just write my 100% solution in as few as 3-4 lines of shell.
Of course shells aren't perfect - but for build tasks they are really good. They handle environments (which, btw, have both encapsulation and inheritance), I/O, subprocesses and file system manipulations with ease. If you do have complex data structures, nothing prevents you to write helper scripts to deal with them, or go the other way around and write shell script generators and at least be honest about it instead of hiding them behind system() or popen() calls.
Build systems would be so much simpler if people accepted shell as a valid tool instead of treating it like some embarrassing relative.
Tuesday, January 3, 2012
node.js - the Third Re-Invention of the Wheel?
I'm just beginning to read up on node.js. I admit I'm intrigued. I specifically like the package manager. It's the first package manager that explicitly supports dependencies with dependencies to different versions of the same package.
Of course, having "source is the binary" and nested folder structures helps...
Adding a blog roll, with the following first entry:
http://www.mikealrogers.com/posts/nodemodules-in-git.html
Of course, having "source is the binary" and nested folder structures helps...
Adding a blog roll, with the following first entry:
http://www.mikealrogers.com/posts/nodemodules-in-git.html
Monday, January 2, 2012
What Is It With "maven"?
Maven is a java based build system, mainly geared towards java development. It follows the convention over configuration pattern and therefore features relatively compact project description files for every artifact to be built. The source tree layout and build process is assumed and inferred, although it can be overridden via configuration, if you must.
The outstanding feature of Maven is the support for prebuilt artifacts. In fact, maven bootstraps itself using the same mechanism used during builds and pulls most of itself from the cloud.
Maven artifacts have an associated metadata file: pom.xml. The file originates in the project source tree building that artifact and is copied into various artifact repositories used during a build.
Maven artifacts are defined and referenced by id and version. Dependencies between artifacts are listed in the pom.xml file. Maven will compute the transitive dependencies and ensure they are available for resolution when needed.
Maven is a system I very much want to like. It implements a build system usable in the many small source trees model of development and just generally provides a nice framework for build automation and reporting. Unfortunately, it has a couple of limitations that make it unsuitable as a general purpose build framework:
Now even though SNAPSHOT dependencies resolve the immediate problem of developers having to edit the dependencies every time, it does create a new problem: what to do at release time. The infamous release plugin addresses it by essentially mass updating all the project files to include the release version, rebuild, then edit them again to reflect the next version to be developed (usually a new SNAPSHOT version). This is bad for many reasons:
The outstanding feature of Maven is the support for prebuilt artifacts. In fact, maven bootstraps itself using the same mechanism used during builds and pulls most of itself from the cloud.
Maven artifacts have an associated metadata file: pom.xml. The file originates in the project source tree building that artifact and is copied into various artifact repositories used during a build.
Maven artifacts are defined and referenced by id and version. Dependencies between artifacts are listed in the pom.xml file. Maven will compute the transitive dependencies and ensure they are available for resolution when needed.
Maven is a system I very much want to like. It implements a build system usable in the many small source trees model of development and just generally provides a nice framework for build automation and reporting. Unfortunately, it has a couple of limitations that make it unsuitable as a general purpose build framework:
- Being java based, it assumes platform independence. It is very hard to adapt it to build C/C++ projects and artifacts.
- The artifact dependencies are required to have explicit versions. This requires frequent updating of the pom.xml files as multiple artifacts are being rebuilt.
- The versions can be specified in a "Master POM" file via the DependencyManagement section. The drawback is that the master POM needs to be available at build time, and you still need to edit it and deal with merges etc.
- Maven has a special version identifier called SNAPSHOT. This can be used in the suffix of any version specification and means essentially: get me the latest build you can find.
Now even though SNAPSHOT dependencies resolve the immediate problem of developers having to edit the dependencies every time, it does create a new problem: what to do at release time. The infamous release plugin addresses it by essentially mass updating all the project files to include the release version, rebuild, then edit them again to reflect the next version to be developed (usually a new SNAPSHOT version). This is bad for many reasons:
- The full source tree needs to be available for this to work. Alternatively you can attempt to release every artifact separately, but then the builds of dependent artifacts need to somehow know the right version, requiring some central place accessible to all artifact builds.
- Forcing a rebuild just to use the new version numbers assumes that builds are trivially reproducible. This is a very difficult requirement to meet in practice. Alternatively, you can produce release candidate builds using the release plugin, and simply throw them away if they do not pass muster, but these builds are then different from development builds, and again you would end up rebuilding many artifacts just for the pleasure of branding them with a new version.
- Use SNAPSHOT as a placeholder for a build id, generated at build time, and use the resulting version number in the artifact name. This is in fact how some artifact repository systems work, but unfortunately this isn't exposed. Most people use a timestamp, as it is as good as anything to instill a reasonable ordering of builds.
- Resolve your SNAPSHOT dependencies by picking the latest build from your list of repositories, and dump out a DependencyManagement section with the resolved versions as part of your build result. This can be used in case someone wishes to attempt a repro of that build.
- Leave the versions in the pom.xml files alone, unless you wish to express an API incompatibility be requiring a new minimal version number.
Why Many Small Source Trees Are Better Than a Single Large One
Now this is a nice bike shed, one where I've changed my mind over time, helped along by the rise of distributed version control systems and build systems like maven.
Essentially, I'm talking about:
The right side addresses the issues created by the left side:
One of the goals of this blog is to describe how a comprehensive system of many small source code repositories can work:
Essentially, I'm talking about:
workspace/ workspace/I used to advocate the left side:
|_src/ |_liba/
|_liba/... vs. | |_src/...
|_libb/... |_libb/
|_prog/... | |_src/...
|_prog/
|_src/...
- Easy to grow into
- Easy to explain
- Easy for build systems, especially after reading Recursive Make Considered Harmful.
- Checkouts become really big - so big that people will be reluctant to create new ones or even recreate an existing one. I've seen places where a mere checkout can take several hours.
- Branching and merging can become expensive, thereby discouraging those essential operations or forcing people to invent shortcuts and hacks to deal with the expense.
- It doesn't deal well with third party software: you are faced with either having to check in and carry around code that you very rarely modify, or you need to go to the right side in the diagram after all (or check in binaries, which is horrid).
- It makes it too easy for developers to permeate API layers, since it's all out there. In the end you get the big ball of mud. Refactoring the ball of mud later on, already a sizable task on its own, is aggravated by the fact that branching and merging has become very expensive.
The right side addresses the issues created by the left side:
- Developers can limit the size of their checkouts to those portions of the code they are modifying, making both the checkouts and branching and merging a lot cheaper.
- Every software component can be assigned a curator or an owner who can vet changes made. You could do this in the large tree also, but having completely separate entities allows you to simplify access controls and configuration, and make the version control systems work for you.
- Third party software just becomes another repository and is treated essentially the same way as your own code.
One of the goals of this blog is to describe how a comprehensive system of many small source code repositories can work:
- I've already explained in my three part series why artifacts are important and how they can be built and released.
- I need to explain how the artifacts will be versioned and tracked. For this, an artifact registry service will be introduced.
- Finally, I need to explain how the build system needs to work to support all this.
Subscribe to:
Posts (Atom)