One important and non-obvious trick of the trade when implementing a branch promotion model is to only promote to your production branch after committing to the deploy or release of the product. Ideally, you promote once you know you will not be rolling back, which could be as late as a week or two after the actual release!
Doing this ensures that while you are certifying your release candidate, you can still perform emergency production patches and not lose them.
In order to do this, it is important to ensure your builds do not depend somehow on the intended deploy target, because you would want to be able to deploy any build no matter where it was made. Doing this ensures that your build artifacts are properly reusable, and no unneeded rebuilds take place.
Monday, January 23, 2012
Saturday, January 21, 2012
Building an Artifact Registry Service (Part 1)
In previous posts, I made the point that builds are precious. Managing the artifacts produced by those builds is a problem that is very similar to source control. In fact, it's so similar that many shops will store build artifacts in the same version control system used for the source itself.
Storing large blobs of binary data in a revision control system has the advantage of simplicity, but also many drawbacks:
Going down the road of having a build system modify source code is a dangerous path. You will need to address the question of how to resolve the inevitable merge conflicts that arise when multiple branches and builds are happening at the same time.
A better way to proceed is to examine how packaging systems resolve these problems. Packaging systems will rarely reference a specific package by version. Usually, the reference is of the form: "I need package X" or "I need at least version 1.3 of package Y". These dependency references need to be edited only rarely, and usually in conjunction with a code change that affects those requirements - and those are perfectly good reasons to edit a source file and cause merge trouble for others.
Packaging systems will then attempt to resolve the dependencies using all the repositories it knows about. This is very similar, btw, to the way most linkers resolve dependencies. You have two components:
So, to recap:
Building a service to do that part is quite simple, as all revision control systems have some method for identifying a source code state:
With a simple service like this, you can already achieve a lot of things. Most importantly, that number can be used to index into an artifact repository, and since that number is monotonically increasing, it is simple to get the latest build of an artifact.
But, as we will see, once we have this service, it becomes the natural storage location for much of the metadata associated with a build:
Storing large blobs of binary data in a revision control system has the advantage of simplicity, but also many drawbacks:
- Revision control systems are optimized for text files and provide features to efficiently diff and merge them. All that machinery is useless for binary blobs.
- Most revision control systems rely on changeset deltas to efficiently store multiple revisions. This doesn't work well for binary blobs, so your storage requirements for your repository goes way up.
- Checking out a local copy of the source tree will retrieve all the binary blobs you could perhaps need, but probably won't need. Due to the time it takes to download all those blobs, people will be reluctant to create multiple checkouts as needed, encouraging the bad practice of developing multiple independent changes in the same workspace. It also encourages use of incremental builds for continuous integration, which poses significant challenges for the build system.
"Version the reference, not the blob."Once you start doing that, another problem crops up: the references change often. If you store the reference in a source file, you will find yourself editing that file very often, or maybe even having the build system edit the file and check it in. Unfortunately, this practice is very common, as various build systems like ant pride themselves in having built-in features to support it.
Going down the road of having a build system modify source code is a dangerous path. You will need to address the question of how to resolve the inevitable merge conflicts that arise when multiple branches and builds are happening at the same time.
A better way to proceed is to examine how packaging systems resolve these problems. Packaging systems will rarely reference a specific package by version. Usually, the reference is of the form: "I need package X" or "I need at least version 1.3 of package Y". These dependency references need to be edited only rarely, and usually in conjunction with a code change that affects those requirements - and those are perfectly good reasons to edit a source file and cause merge trouble for others.
Packaging systems will then attempt to resolve the dependencies using all the repositories it knows about. This is very similar, btw, to the way most linkers resolve dependencies. You have two components:
- What you need (think -l flag);
- Where to find it (think -L flag).
So, to recap:
- Checking in binary blobs in revision control systems is bad;
- Checking in explicit references into source files is slightly better, but still bad if those references change often (as they will in a live software development project)
- Checking in references as requirements and using a system to resolve those requirements using a source of knowledge of what is available is good.
- A set of artifact repositories
- A registry service or indexing service to help you locate the right artifact for your build and track exactly what the artifact consists of.
- It must map to a specific feature set (i.e. source code state)
- It must increase monotonically over time (i.e. a higher number means a newer version)
major.minor.patch.buildnr
The trick is to let humans worry about the major.minor.patch bikeshed,
but let the build number be generated automatically. As long as the
build number by itself fulfills our two conditions above, we're good.
Building a service to do that part is quite simple, as all revision control systems have some method for identifying a source code state:
- svn and perforce have changeset numbers that already display good monotonic behavior;
- git and mercurial have changeset hashes, which would need to be converted to numbers by our registry service;
- Any system will at minimum have a unique id for every file revision, and a changeset can be defined as the hash constructed from the sorted list of all the file revisions touched by that change. Pass that hash to the registry service and obtain the number.
http://<someplace.com>/ars/changeset/<hash>returning a number, either the number already assigned to the given hash, or a new number if that hash is not known to the system, and:
http://<someplace.com>/ars/build/<nr>delivering back the hash associated with the build.
With a simple service like this, you can already achieve a lot of things. Most importantly, that number can be used to index into an artifact repository, and since that number is monotonically increasing, it is simple to get the latest build of an artifact.
But, as we will see, once we have this service, it becomes the natural storage location for much of the metadata associated with a build:
- artifact name
- artifact repository location(s)
- platforms and variants built
- changesets included in that build
- dependencies included in that build
- source code repository location(s) used in the build
- ...
Thursday, January 12, 2012
Versions in Branch Names Considered Harmful
Several bikesheds for the price of one here. I'll skip the bikeshed on how to actually generate version numbers and just explain why you shouldn't use version numbers in branch names.
A common release branching strategy looks like this:
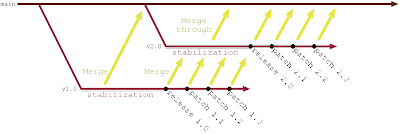
The idea is that when you have a conflict between work required for the current release and work for the next release, you create a release branch. Whatever the timing of the branch creation is, there is a temptation to create a new branch for every release.
There are some trade-offs in doing this:
Instead, I advocate for role based branching. We observe that the release branches really serve two roles: stabilization and patching. So instead of performing these activities on the same branch, we copy (promote) the code from one branch to the next until we end up in the production (or hotfix) branch, where patches can be applied:
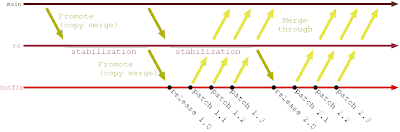
The tradeoffs here are different:
To Summarize:
A common release branching strategy looks like this:

The idea is that when you have a conflict between work required for the current release and work for the next release, you create a release branch. Whatever the timing of the branch creation is, there is a temptation to create a new branch for every release.
There are some trade-offs in doing this:
- You do know where you're at, so that's good;
- If you need to support many older releases at the same time, it is easy to out the right place to patch;
- You need to track what the "current" branch is, especially if you wish to use automated deploys;
- You need to actively verify whether the merges back into your mainline have been performed.
- You could, in theory, work on stabilizing multiple releases concurrently.
Instead, I advocate for role based branching. We observe that the release branches really serve two roles: stabilization and patching. So instead of performing these activities on the same branch, we copy (promote) the code from one branch to the next until we end up in the production (or hotfix) branch, where patches can be applied:

The tradeoffs here are different:
- You can only work on one stabilization at a time ;
- Patching the latest release is easy, but patching older releases is more complicated, as you need to create an ad-hoc branch at that release, patch there, then merge through;
- You always know where your current release branch and your current patch (hotfix) branch is;
- Configuring automated deploys to test environments is easy, as the source locations are constant;
- If the merge through steps have been omitted, you find out when you try to promote, as this merge will no longer be a copy merge.
- The total number of branches known to your version control system is reduced.
To Summarize:
- Use branches to reflect the role or the state of the code contained in the branch;
- Use labels to reflect versions;
- Merge stable code into unstable code and resolve in the unstable branches;
- Ensure that promotions are true copy merges.
Tuesday, January 10, 2012
The Strange Aversion Against Shells
I keep running into code that looks like this:
Yeah, so shells are 30 years old or more - and that's a problem, because? At least they're stable and ubiquitous. On Windows? Get CygWin - yeah, not perfect, but then again, you're on Windows, right?
It gets worse: people hate on old tools like GNU Make, only to create ant. Really? A dependency management language in XML where the execution portion is in java?
If I need a custom action and use Make, I write the rule and the dependencies, and then I write a <gasp> shell script indented by (oh noes) tabs. Done.
If I need a custom action in ant, I need a java IDE, a java build system (probably ant - with fun bootstrapping issues to go along), a deploy strategy to ensure that ant actually uses my plugin, and I still end up writing code looking strangely like shell scripts....
To be cool, I should precede that with exhaustive research on whether there already isn't a plugin that sort of kind of does what I need and think about whether I can live with the 80% solution when I can just write my 100% solution in as few as 3-4 lines of shell.
Of course shells aren't perfect - but for build tasks they are really good. They handle environments (which, btw, have both encapsulation and inheritance), I/O, subprocesses and file system manipulations with ease. If you do have complex data structures, nothing prevents you to write helper scripts to deal with them, or go the other way around and write shell script generators and at least be honest about it instead of hiding them behind system() or popen() calls.
Build systems would be so much simpler if people accepted shell as a valid tool instead of treating it like some embarrassing relative.
$command = "utility arg1 arg2";or worse:
FH = open("$command |");
while (<FH>) {
if /regexp/ ....
args = []Why are people so averse to actually writing shell scripts instead of embedding shell scripts into other scripting languages?
if opt.long: args.append("-l")
if opt.quiet: args.append("-q")
...
system(command, args)
Yeah, so shells are 30 years old or more - and that's a problem, because? At least they're stable and ubiquitous. On Windows? Get CygWin - yeah, not perfect, but then again, you're on Windows, right?
It gets worse: people hate on old tools like GNU Make, only to create ant. Really? A dependency management language in XML where the execution portion is in java?
If I need a custom action and use Make, I write the rule and the dependencies, and then I write a <gasp> shell script indented by (oh noes) tabs. Done.
If I need a custom action in ant, I need a java IDE, a java build system (probably ant - with fun bootstrapping issues to go along), a deploy strategy to ensure that ant actually uses my plugin, and I still end up writing code looking strangely like shell scripts....
To be cool, I should precede that with exhaustive research on whether there already isn't a plugin that sort of kind of does what I need and think about whether I can live with the 80% solution when I can just write my 100% solution in as few as 3-4 lines of shell.
Of course shells aren't perfect - but for build tasks they are really good. They handle environments (which, btw, have both encapsulation and inheritance), I/O, subprocesses and file system manipulations with ease. If you do have complex data structures, nothing prevents you to write helper scripts to deal with them, or go the other way around and write shell script generators and at least be honest about it instead of hiding them behind system() or popen() calls.
Build systems would be so much simpler if people accepted shell as a valid tool instead of treating it like some embarrassing relative.
Tuesday, January 3, 2012
node.js - the Third Re-Invention of the Wheel?
I'm just beginning to read up on node.js. I admit I'm intrigued. I specifically like the package manager. It's the first package manager that explicitly supports dependencies with dependencies to different versions of the same package.
Of course, having "source is the binary" and nested folder structures helps...
Adding a blog roll, with the following first entry:
http://www.mikealrogers.com/posts/nodemodules-in-git.html
Of course, having "source is the binary" and nested folder structures helps...
Adding a blog roll, with the following first entry:
http://www.mikealrogers.com/posts/nodemodules-in-git.html
Monday, January 2, 2012
What Is It With "maven"?
Maven is a java based build system, mainly geared towards java development. It follows the convention over configuration pattern and therefore features relatively compact project description files for every artifact to be built. The source tree layout and build process is assumed and inferred, although it can be overridden via configuration, if you must.
The outstanding feature of Maven is the support for prebuilt artifacts. In fact, maven bootstraps itself using the same mechanism used during builds and pulls most of itself from the cloud.
Maven artifacts have an associated metadata file: pom.xml. The file originates in the project source tree building that artifact and is copied into various artifact repositories used during a build.
Maven artifacts are defined and referenced by id and version. Dependencies between artifacts are listed in the pom.xml file. Maven will compute the transitive dependencies and ensure they are available for resolution when needed.
Maven is a system I very much want to like. It implements a build system usable in the many small source trees model of development and just generally provides a nice framework for build automation and reporting. Unfortunately, it has a couple of limitations that make it unsuitable as a general purpose build framework:
Now even though SNAPSHOT dependencies resolve the immediate problem of developers having to edit the dependencies every time, it does create a new problem: what to do at release time. The infamous release plugin addresses it by essentially mass updating all the project files to include the release version, rebuild, then edit them again to reflect the next version to be developed (usually a new SNAPSHOT version). This is bad for many reasons:
The outstanding feature of Maven is the support for prebuilt artifacts. In fact, maven bootstraps itself using the same mechanism used during builds and pulls most of itself from the cloud.
Maven artifacts have an associated metadata file: pom.xml. The file originates in the project source tree building that artifact and is copied into various artifact repositories used during a build.
Maven artifacts are defined and referenced by id and version. Dependencies between artifacts are listed in the pom.xml file. Maven will compute the transitive dependencies and ensure they are available for resolution when needed.
Maven is a system I very much want to like. It implements a build system usable in the many small source trees model of development and just generally provides a nice framework for build automation and reporting. Unfortunately, it has a couple of limitations that make it unsuitable as a general purpose build framework:
- Being java based, it assumes platform independence. It is very hard to adapt it to build C/C++ projects and artifacts.
- The artifact dependencies are required to have explicit versions. This requires frequent updating of the pom.xml files as multiple artifacts are being rebuilt.
- The versions can be specified in a "Master POM" file via the DependencyManagement section. The drawback is that the master POM needs to be available at build time, and you still need to edit it and deal with merges etc.
- Maven has a special version identifier called SNAPSHOT. This can be used in the suffix of any version specification and means essentially: get me the latest build you can find.
Now even though SNAPSHOT dependencies resolve the immediate problem of developers having to edit the dependencies every time, it does create a new problem: what to do at release time. The infamous release plugin addresses it by essentially mass updating all the project files to include the release version, rebuild, then edit them again to reflect the next version to be developed (usually a new SNAPSHOT version). This is bad for many reasons:
- The full source tree needs to be available for this to work. Alternatively you can attempt to release every artifact separately, but then the builds of dependent artifacts need to somehow know the right version, requiring some central place accessible to all artifact builds.
- Forcing a rebuild just to use the new version numbers assumes that builds are trivially reproducible. This is a very difficult requirement to meet in practice. Alternatively, you can produce release candidate builds using the release plugin, and simply throw them away if they do not pass muster, but these builds are then different from development builds, and again you would end up rebuilding many artifacts just for the pleasure of branding them with a new version.
- Use SNAPSHOT as a placeholder for a build id, generated at build time, and use the resulting version number in the artifact name. This is in fact how some artifact repository systems work, but unfortunately this isn't exposed. Most people use a timestamp, as it is as good as anything to instill a reasonable ordering of builds.
- Resolve your SNAPSHOT dependencies by picking the latest build from your list of repositories, and dump out a DependencyManagement section with the resolved versions as part of your build result. This can be used in case someone wishes to attempt a repro of that build.
- Leave the versions in the pom.xml files alone, unless you wish to express an API incompatibility be requiring a new minimal version number.
Why Many Small Source Trees Are Better Than a Single Large One
Now this is a nice bike shed, one where I've changed my mind over time, helped along by the rise of distributed version control systems and build systems like maven.
Essentially, I'm talking about:
The right side addresses the issues created by the left side:
One of the goals of this blog is to describe how a comprehensive system of many small source code repositories can work:
Essentially, I'm talking about:
workspace/ workspace/I used to advocate the left side:
|_src/ |_liba/
|_liba/... vs. | |_src/...
|_libb/... |_libb/
|_prog/... | |_src/...
|_prog/
|_src/...
- Easy to grow into
- Easy to explain
- Easy for build systems, especially after reading Recursive Make Considered Harmful.
- Checkouts become really big - so big that people will be reluctant to create new ones or even recreate an existing one. I've seen places where a mere checkout can take several hours.
- Branching and merging can become expensive, thereby discouraging those essential operations or forcing people to invent shortcuts and hacks to deal with the expense.
- It doesn't deal well with third party software: you are faced with either having to check in and carry around code that you very rarely modify, or you need to go to the right side in the diagram after all (or check in binaries, which is horrid).
- It makes it too easy for developers to permeate API layers, since it's all out there. In the end you get the big ball of mud. Refactoring the ball of mud later on, already a sizable task on its own, is aggravated by the fact that branching and merging has become very expensive.
The right side addresses the issues created by the left side:
- Developers can limit the size of their checkouts to those portions of the code they are modifying, making both the checkouts and branching and merging a lot cheaper.
- Every software component can be assigned a curator or an owner who can vet changes made. You could do this in the large tree also, but having completely separate entities allows you to simplify access controls and configuration, and make the version control systems work for you.
- Third party software just becomes another repository and is treated essentially the same way as your own code.
One of the goals of this blog is to describe how a comprehensive system of many small source code repositories can work:
- I've already explained in my three part series why artifacts are important and how they can be built and released.
- I need to explain how the artifacts will be versioned and tracked. For this, an artifact registry service will be introduced.
- Finally, I need to explain how the build system needs to work to support all this.
Subscribe to:
Posts (Atom)