In the past I've been quite skeptical of the "best practice" of tagging builds. Build tags just clutter up your repository and can actually cause real performance issues on large git repositories and large number of builds.
I am evolving on this issue though, and have come to appreciate build tags for an unexpected reason: they are a wonderful place to stash build metadata.
Any complex build will have to resolve dependency graphs. Modern build systems seem to encourage the use of "dynamic" dependencies, which have the advantage of requiring less effort to specify, and automatically "upgrade" as new releases become available.
The disadvantage of dynamic dependencies is that they lead to non-reproducible builds, and also often lead to unexpected breakage when some third party produces a buggy release or breaks the implicit contract in the semantic version scheme.
Therefore, it is generally good practice to archive the results of a dependency resolution pass someplace, so that you can always revert back to a known good version, and also reliably reproduce a specific build if needed.
Most build systems have some form of support for this. Node, for example, has shrinkwrap, and gradle has a dependency lock plugin. All these mechanisms rely on dumping out the actual resolution to a file, and have the ability to use that file to impose a pre-determined resolution onto a new build.
In practice, though, this is hard to do. If you check the file into git, then your build may have to resolve merge conflicts on that file - which can be difficult to automate. You also lose the implicit linkage between the git commit that was built and the contents of the file. In other words, if you change the dynamic dependency specification, then the contents of the persisted file no longer has any relationship to that specification, so it should really be deleted. Nobody will ever remember to do that...
I think that attaching the resolution file as an annotation to a git tag is the right solution. It has all the correct properties:
- It is unique to the git commit used for the build
- There is no merge conflict, it can easily be done even if newer git commits exist
- The presence or absence of a build tag on some git commit can be automatically detected and used to control whether the predetemined resolution should be used (i.e. when we are rebuilding an old build), and when a new resolution needs to be done.
- If the result of the resolution becomes invalid, you can simply delete the build tag.
So how does one deal with the clutter of many build tags?
One solution is to delete old build tags - but that is kind of sad, as you lose source data for a variety of historical stats. If you care about the stats, you suddenly need to find a different place to store the data.
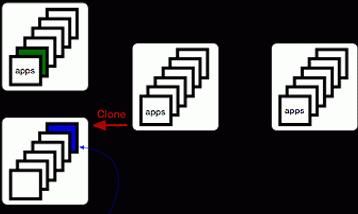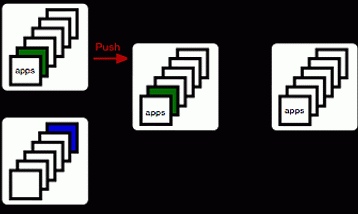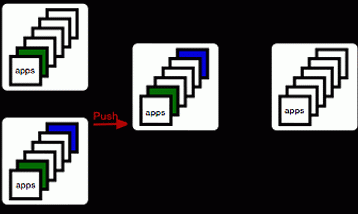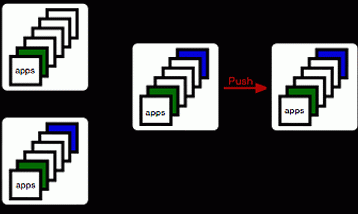
Fortunately, git is a very versatile system, and there are alternatives. For example, you can stash them in a different ref on your central server. So when you apply a tag, you do this:
% git tag -m 'Annotation' MYTAG
% git push origin refs/tags/MYTAG:refs/builds/tags/MYTAG
Normally, you'd push them into refs/tags/, but by pushing them into refs/builds/tags/, they will not be "seen" by the default refspec, so normal developer git pull commands stay fast and efficient.
If they want to see the build tags, they can pull them in trivially using this:
% git fetch origin 'refs/builds/tags/*:refs/tags/*'
And if they want to remove them again from their local repo, they run:
% git fetch --prune origin 'refs/tags/*:refs/tags/*'