We are in business providing some sort of service. We write software to implement pieces of the service we're offering. This software needs to run someplace. That someplace is the environment.
In traditional shrink wrap software, the environment was often the user's desktop, or the enterprise's data center. The challenge then was to make our software be as robust as possible in hostile environments over which we had little control.
The next step on the evolutionary ladder was the appliance. Something we could control to some extent, but it still ends up sitting on a location and in a network outside our control.
The final step is software as a service, where we control all aspects of the hosts running our applications.
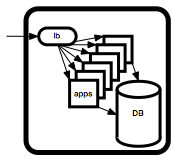
From a build and release perspective, what matters is what we can control. So it makes sense to define an environment as a set of hardware and software assembled for the purpose of running our applications and services.
A typical environment for a web service might look like the diagram on the right.
So an environment is essentially:
Hardware
OS
Third Party Tools
Our Apps
+ Configuration
====================
Environment
In the shrink wrap world, it is common to maintain a whole bank of machines and environments, hopefully replicating the majority of the setups used by our customers.
In the software as a service world, the issue is how well we can emulate our own production environment. For large scale popular services, this can be very expensive to do. There are also issues around replicating the data. Often, regulatory requirements and even common sense security requirements preclude making a direct copy of personally identifiable data.
This being said, modern virtualization and volume management addresses many of the issues encountered when attempting to duplicate environments. It's still not easy, but it is a lot easier than it used to be.
If you have the budget, it is very worthwhile to automate the creation of new environments as clones of existing ones at will. If you can at least achieve this for 5-7 environments, you can adopt an iterative refinement process, very similar to the way you manage code in version control systems.
We start by cloning our existing production environment to create a new release candidate environment. This one will evolve to become our next release.

To update a set of apps, we first again clone the release candidate environment, creating a sandbox environment to test both the deploy process and the resulting functionality.

Then, we deploy one or more updated applications, freshly built from our continuous build service (aka Jenkins, TeamCity, or other).
The technical details on how the deploy happens are important, but not the central point here. I first want to highlight the workflow.
Now, let's suppose a different group is working on a different set of apps at the same time.

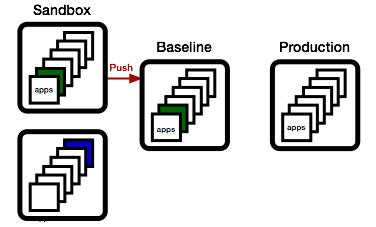
Meanwhile, QA has been busy, and the green app has been found worthy. As a consequence, we promote the sandbox environment to the release candidate environment.
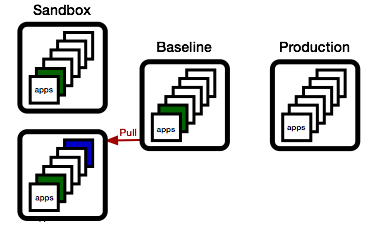
Now, if the blue team wishes to promote their changes, they first need to sync up. They do this by updating their sandbox with all apps in the baseline that are newer than the apps they have.
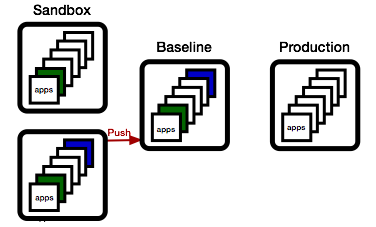
... and if the baseline meets the release criteria, we push to production.
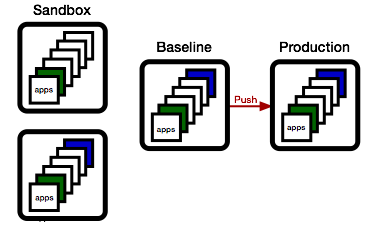
This process should feel very familiar. It's nothing else but the basic change process as we know it from version control systems, just applied to environments:
- We establish a baseline
- We check out a version
- We modify the version
- We check if someone else modified the baseline
- If yes, we merge from the baseline
- We check in our version.
- We release it if it's good.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.