In an earlier post, I explained the basic change process. In this post I'd like to show how it works in a distributed version control system. Besides encouraging the general use of distributed version control systems, I'd like to expose the difference between the classic branching diagrams and the actual meaningful part of the revision history.
 As a reminder, here's the branch diagram again:
As a reminder, here's the branch diagram again:- Start at a stable revision;
- Branch, make change;
- Meanwhile, some other change makes it into the stable branch;
- Pull in the new change, merge;
- Add your change to the stable branch (assuming, of course, it passes QA).
Here's what it looks like in the distributed world:
 You start with your main repository. This will usually be hosted on some kind fo more centralized host, or on a service like GitHub or bit bucket. As I explained in my Cherrypicking Made Easy post, the best repo to use is the one that represents your current production version of the code. I believe that in the end, this is the only repository that truly matters to Release Management...
You start with your main repository. This will usually be hosted on some kind fo more centralized host, or on a service like GitHub or bit bucket. As I explained in my Cherrypicking Made Easy post, the best repo to use is the one that represents your current production version of the code. I believe that in the end, this is the only repository that truly matters to Release Management...
If you wish to make a change, you fork or clone your own repository off the main repo. If you use a remote service, you may wish to first fork/clone the repo on that remote service, then clone onto your local machine.
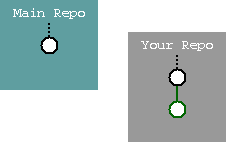 Now edit, compile, test and check in - creating the green revision in the diagram.
Now edit, compile, test and check in - creating the green revision in the diagram.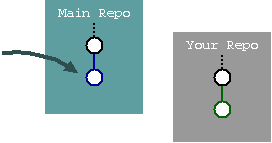
Meanwhile, some other change appears in the main repository, marked as the blue change.
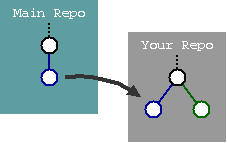


The interesting thing here is how the branching diagram of the basic change process simplifies into the diamond shaped revision graph. This will become more interesting as we examine the basic technique to produce Release Notes by examining changes contributing to a specific revision (usually a release).
A very good read to get into the mood of distributed version control systems is http://hginit.com, especially if you're a subversion or perforce user.
I'm not sure that I agree with you that the owner of the main repo should pull changes. In a collaborative environment where you want to control the selection of submitted features, I would buy that argument. In my experience, merging other people's code is notoriously error-prone, and the best person to do the job is the change author. You also have more accountability from both sides - my feature, my merge, my bugs to fix, and my issues to correct if my merge clobbered some other functionality.
ReplyDeleteOne doesn't exclude the other. You pull in any other changes, resolve the merge in your repo, and then make the pull request, asking the curator of the authoritative repo to pull in your merge.
ReplyDeleteIf at that point, the curator of the repo notices a merge conflict, he can simply reject the pull request and ask you to perform a pull/merge yourself first.