Then again, ignoring isn't always an option...
So, why don't we just tag the released code?
Back in the days, when software was a small set of executable programs linked from a small set of libraries, this was a simple thing to do. Usually, the whole build was done from a single source tree in one pass, and there never was any ambiguity over which version of each file was used in a build.
The modern days aren't that simple anymore. These days, we build whole suites of services, built from a large set of libraries, often using many different versions of the same library at the same time. Why? mainly because folks don't care to rebuild working services just because one or two dependencies changed.
Furthermore, we also use build systems like maven, based on ivy and similar artifact management tools, and other packaging tools which allow anyone to specify precisely which version of a piece of shared code they wish to use for their particular service or executable. As a side effect, we also get faster builds simply because we avoid rebuilding many libraries and dependencies.
Most people will opt for the "what I know can't hurt me, so why take a chance" approach and resist upgrading dependencies until forced to do so, either because they wish to use a new feature, or for security reasons.
Therefore, in any production environment, you will see many different versions of the same logical entity used at the same time, so tagging a single revision in the source tree of a shared piece of code is impossible. Many revisions need to be tagged.
So here's what I currently do:
First, I use Build Manifests. These contain both the dependency relationship between various build objects, and their specific VCS revision ids.
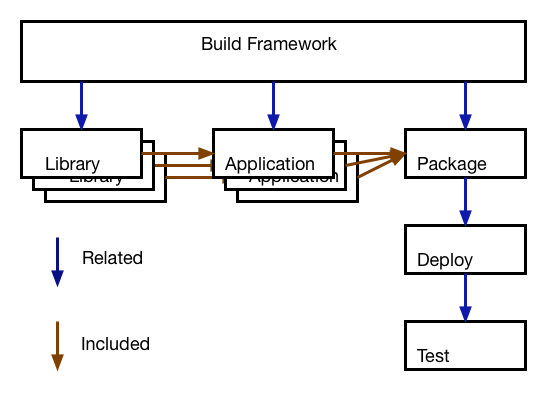
Next, I identify the top level items. These are usually the pieces delivering the actual shippable item, either a service or an executable, or some other package. Every one of these top level items will have a unique human readable name, and a version. This is what I use as the basic tag name.
So my tag names end up looking like this:
<prefix>-<YYYY-MM-DD>-<top-level-name>-<version>[+<dependency-path>]
The date stamp is essentially just there to easily sort the tags and group related versions of related services together, and also to keep tags unique and help locate any bugs in the tagging process. They could be omitted in a perfect world.
With this I run my tagger once a day, retrieving the build manifests from the final delivery area (could be our production site, could be our download site, or wherever the final released components live). We do this to act as a cross-check for the release process. If we find something surprising there, then we know our release process is broken someplace.
The tagger will start with every top level item and generate the tag name, then traverse the dependency list, adding an id for every dependency build used in the top level item. Unless the revision used to build the dependency has already been tagged, it will get the tag with the dependency path.
When checking whether a specific revision is already tagged, I deliberately ignore the date portion and the dependency path portions of the tag and only check the name and version part. This will avoid unnecessary duplication of tags.
In the end, you will get:
- One tag for every top level source tree
- At least one tag for every dependency. You might get many tags in any specific shared code source tree, depending on how the dependency was used in the top level item. My current record is three different revisions of the same piece of shared code used in the same top level item. Dozens of different revisions are routinely used in one production release (usually containing many top level items).
Updated: grammar, formatting and clarity.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.