 To demonstrate the challenges involved with modern "agile" processes, let's take a relatively simple scenario: two applications or services, each depending on a piece of shared code.
To demonstrate the challenges involved with modern "agile" processes, let's take a relatively simple scenario: two applications or services, each depending on a piece of shared code.In the good old days, this was somewhat of a no-brainer. All pieces would live in the same source tree, and be built together.
{kind=link}
A single version control repository would be used, and a release consists of all components, built once.
A new release consists of rebuilding all pieces and delivering them as a unit. So finding the difference between two releases was a pure version control system operation, and no additional thinking was required.
 The challenge in the bad old days was that every single one of your customers probably had a different version of your system, and was both demanding in fixing their bugs, but refusing to upgrade to your latest release. Therefore you had to manage lots of patch branches.
The challenge in the bad old days was that every single one of your customers probably had a different version of your system, and was both demanding in fixing their bugs, but refusing to upgrade to your latest release. Therefore you had to manage lots of patch branches.Still, everything was within the confines of a single version control repository, and figuring out the deltas between two releases was essentially running:
git log <old>..<new>In the software as a service model, you don't have the patching problem. Instead, you have the challenge of getting your fixes out to production as fast and as safely as possible.
 The mantra here is: if it ain't broke, don't fix it. As we've seen before, rebuilding and re-releasing an unchanged component already can have risks, and forcing a working component to be rebuilt because of unrelated changes will at least cause delay.
The mantra here is: if it ain't broke, don't fix it. As we've seen before, rebuilding and re-releasing an unchanged component already can have risks, and forcing a working component to be rebuilt because of unrelated changes will at least cause delay.So, to support the new world, we split our single version control repository into separate repositories, one for each component. The components get built separately, and can be released separately.
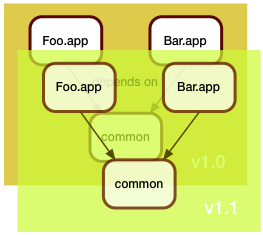
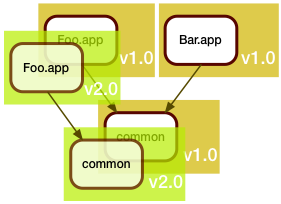 In this example, Foo.app got updated. This update unfortunately also required a fix to the shared code library. Arguably, Bar.app should be rebuilt to see if the fix broke it, but we are in a hurry (when are we ever not in a hurry?), and since Bar.app is functioning fine as is, we don't rebuild it. We just leave it alone.
In this example, Foo.app got updated. This update unfortunately also required a fix to the shared code library. Arguably, Bar.app should be rebuilt to see if the fix broke it, but we are in a hurry (when are we ever not in a hurry?), and since Bar.app is functioning fine as is, we don't rebuild it. We just leave it alone.As we deploy this to production, we realize we now have two different versions of common there.
That in itself is usually not a problem if we build things right, for example by using "assemblies", using static linking, or just paying attention to the load paths.
I sometimes joke that the first thing everyone does in a C++ project is to override new. The first thing everyone does in a Java project is to write their own class loader. This scenario explains why.
But with this new process, answering the question of "What's new in production?" is no longer a simple version control operation. For one, there isn't a single repository anymore - and then the answer depends on the service or application you're examining.
In this case, the answer would be:
Bar.app: unchangedIn order to divine this somehow, we need to register the exact revisions used for every piece of the build. I personally like build manifests embedded someplace in the deliverable items. These build manifests would include all the dependency information, and would look somewhat like this:
Foo.app: git log v1.0..v2.0 # in Foo.app's repo
git log v1.0..v2.0 # in common's repo
{ "Name": "Foo.app",The same idea can be used to describe the state of a complete release. We just aggregate all the build manifests into a larger one:
"Rev": "v2.0",
"Includes": [ { "Name": "common",
"Rev": "v2.0" } ] }
{ "Name": "January Release",
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v1.0" }]}]}
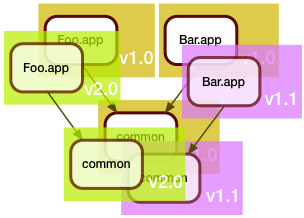 Now the development team around Bar.app wasn't idle during all this time, and they also came up with some changes. They too needed to update the shared code in common.
Now the development team around Bar.app wasn't idle during all this time, and they also came up with some changes. They too needed to update the shared code in common.Of course, they also were in a hurry, and even though they saw that the Foo.app folks were busy tweaking the shared code, they decided that a merge was too risky for their schedule, and instead branched the common code for their own use.
When they got it all working, the manifest of the February release looked like this:
{ "Name": "February Release",It should be easy to see how recursive traversal of both build manifests will yield the answer to the question "What changed between January and February?":
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.1",
"Includes": [{ "Name": "common",
"Rev": "v1.1" }]}]}
Foo.app: unchanged
Bar.app: git log v1.0..v1.1 # in Bar.app's repo
git log v1.0..v1.1 # in common's repo
 So far, this wasn't so difficult. Where things get interesting is when a brand new service comes into play.
So far, this wasn't so difficult. Where things get interesting is when a brand new service comes into play.Here, the folks who developed New.app decided that they will be good citizens and merge the shared code in common. "Might as well", they thought, "someone's gotta deal with the tech debt".
Of course, the folks maintaining Foo.app and Bar.app would have none of it: "if it ain't broke, don't fix it", they said, and so the March release looked like this:
{ "Name": "March Release",So, what changed between February and March?
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.1",
"Includes": [{ "Name": "common",
"Rev": "v1.1" }]},
{ "Name": "New.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v2.1" }]}]}
Foo.app: unchangedThe first part of the answer is easy. Since New.app's repository is brand new, it only makes sense to include all changes.
Bar.app: unchanged
New.app: ????
Foo.app: unchangedOne can make a reasonable argument that from the point of view of New.app, all the changes in common are also new, so they should be listed. In practice, though, this could be a huge list, and wouldn't really be that useful, as most changes would be completely unrelated to New.app, and also would be unrelated to anything within the new release. We need something better.
Bar.app: unchanged
New.app: git log v1.0 # in New.app's repository
and then ????
I think the best answer is: "all changes between the oldest change seen by the other apps, and the change seen by the new app". Or another way to put it: all changes made by the other apps that are ancestors of the changes made by the new app. This would be:
Foo.app: unchangedBut how do we code this?
Bar.app: unchanged
New.app: git log v1.0 # in New.app
git log v2.1 ^v2.0 ^v1.1 # in common
A single recursive traversal of the build manifests is no longer enough. We need to make two passes.
The first pass will compare existing items vs existing items, each registering the revision ranges used for every repository.
The second pass processes the new items, now using the revision ranges accumulated in the first pass to generate the appropriate git log commands for all the dependencies of each new item.
This method seems to work right in all the corner cases:
- If a dependency is brand new, it won't get traversed by any other app, so the list of revisions to exclude in the git log command (the ones prefixed with ^) will be empty, resulting in a git command to list all revisions - check.
- If the new app uses a dependency as is, not modified by any other app, then the result will be revision ranges bound by the same revisions, thereby producing no new changes - check.
Notes:
- In the examples here, I used tags instead of git revision hashes. This was simply done for clarity. In practice, I would only ever apply tags at the end of the release process, never earlier. After all, the goal is to create tags reflecting the state as it is, not as it should be.
- The practice of manually managing your dependencies has unfortunately become quite common in the java ecosystem. Build tools like maven and ivy support this process, but it has a large potential to create technological debt, as the maintainers of individual services can kick the can down the road for a long time before having to reconcile their use of shared code with other folks. Often, this only happens when a security fix is made, and folks are forced to upgrade, and then suddenly all that accumulated debt comes due. So if you wonder why some well known exploits still work on some sites, that's one reason...
- Coding the traversal makes for a nice exercise and interview question. It's particularly tempting to go for premature optimization, which then comes back to bite you. For example, it is tempting to skip processing an item where the revision range is empty (i.e. no change), but in that case you might also forget to register the range, which would result in a new app not seeing that an existing app did use the item...
- Obviously, collecting release notes is more than just collecting commit comments, but this is, I think, the first step. Commit comments -> Issue tracker references -> Release Notes. The last step will always be a manual one, after all, that's where the judgement comes in.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.