
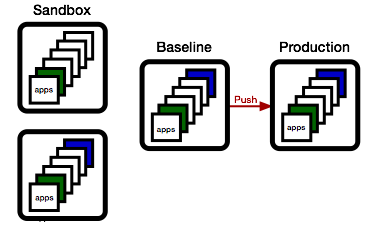
Too busy?
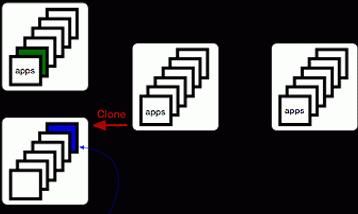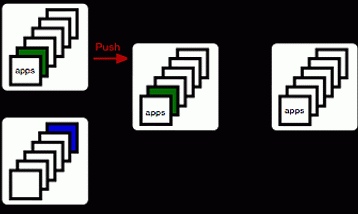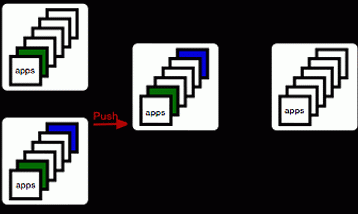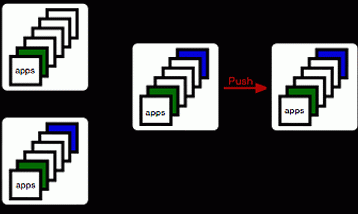
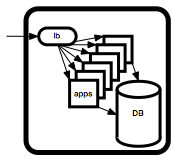
Hardware
OS
Third Party Tools
Our Apps
+ Configuration
====================
Environment



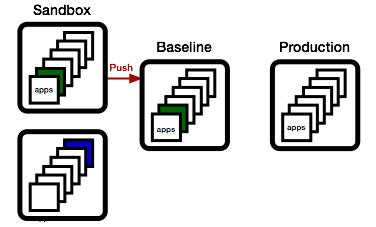
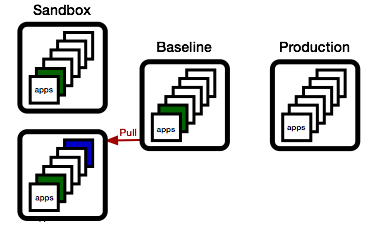
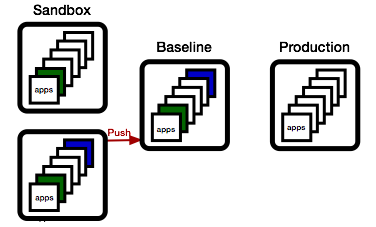

Major version X (X.y.z | X > 0) MUST be incremented if any backwards incompatible changes are introduced to the public APIA new major version will break non-updated consumers of the package. That's a big deal. In practice, you will not be able to perform a major version update without some form of transition plan, during which both the old and the new version must be available.
A Release consists of the new or changed software and/or hardware required to implement approved changes. Release categories include:Even though this definition does pretty much represent a consensus impression of the nature of a release, I think the definition, besides being too focused on implementation details, places too much emphasizes on "change".Releases can be divided based on the release unit into:
- Major software releases and major hardware upgrades, normally containing large amounts of new functionality, some of which may make intervening fixes to problems redundant. A major upgrade or release usually supersedes all preceding minor upgrades, releases and emergency fixes.
- Minor software releases and hardware upgrades, normally containing small enhancements and fixes, some of which may have already been issued as emergency fixes. A minor upgrade or release usually supersedes all preceding emergency fixes.
- Emergency software and hardware fixes, normally containing the corrections to a small number of known problems.
- Delta release: a release of only that part of the software which has been changed. For example, security patches.
- Full release: the entire software program is deployed—for example, a new version of an existing application.
- Packaged release: a combination of many changes—for example, an operating system image which also contains specific applications.
A validated snapshot published to a point of production with a commitment by the stakeholders to not roll back.I think this captures the essence better:
% git log -1 5a434aAttach the tag, like this:
commit 5a434ac808d9a5c10437b45b06693cf03227f6b3
Author: Christian Goetze <cgoetze@miaow.com>
Date: Wed May 29 12:57:57 2013 -0700
TECHOPS-218 Render superceded messages.
% git tag -m "new commit message" CANCEL_5a434a 5a434aNow, the build and deploy scripts can mine this information. They start by listing all the tags attached to the commit:
% git show-ref --tags -d \Then, for every tag, we check whether it's an annotated tag:
| grep '^'5a434a \
| sed -e 's,.* refs/tags/,,' -e 's/\^{}//'
% git describe --exact-match CANCEL_5a434aNote that this command fails if it's a "lightweight" tag. Once you know it's an annotated tag, you can run:
CANCEL_5a434a
% git cat-file tag CANCEL_5a434aThis is easy to parse, and can be used as a replacement for the commit comment.
object 5a434ac808d9a5c10437b45b06693cf03227f6b3
type commit
tag CANCEL_5a434a
tagger Christian Goetze <cgoetze@miaow.com> 1369865583
new commit message
grab mydatabase/mytestThis will create a shared lock on mydatabase, and an exclusive lock on mydatabase/mytest.
grab mydatabase/yourtestthen the shared lock request for mydatabase is merged, and that task will also be at the head of the queues for all of its resources, and can proceed.
grab mydatabaseSince mydatabase here is at the end of the resource path, it will request an exclusive lock which will not be merged with the previous ones, but queued after them. The cleanup task will have to wait until all of the owners of the shared lock release their part, and only then can it proceed.
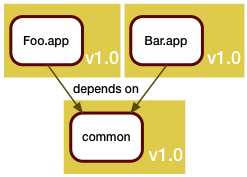
{ "Name": "January Release",
"Includes: [{ "Name": "Foo.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v1.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v1.0" }]}]}

{ "Name": "January Release",In the previous post of the series, we cheated by only modifying one endpoint at a time, and leaving the other one unchanged. Now we change both, and it turns out the answer depends on how you ask the question:
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.1",
"Includes": [{ "Name": "common",
"Rev": "v1.1" }]}]}
Bar.app: git log ^v1.0 v1.1 # in Bar.app
git log ^v1.0 v1.1 # in common
Foo.app: git log ^v1.0 v2.0 # in Foo.app
git log ^v1.0 v2.0 # in common
whole: git log ^v1.0 v1.1 # in Bar.appWhy bring this up? Well, in the previous post I made an argument that it is not only convenient, but necessary to combine the start points of the revision ranges used to get the changes. The same is not true for the end points, as we cannot by any means claim that v2.0 of common is actually in use by Bar.app.
git log ^v1.0 v2.0 # in Foo.app
git log ^v1.0 v1.1 v2.0 # in common
git log ^startpoint1 ^startpoint2 ... endpointand register the commits and the entry points to which they belong.
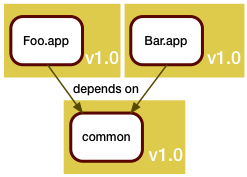
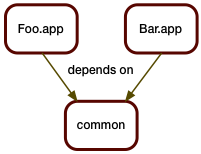 To demonstrate the challenges involved with modern "agile" processes, let's take a relatively simple scenario: two applications or services, each depending on a piece of shared code.
To demonstrate the challenges involved with modern "agile" processes, let's take a relatively simple scenario: two applications or services, each depending on a piece of shared code.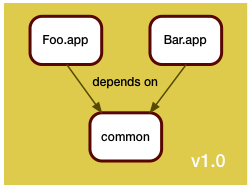
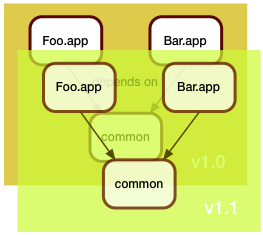 The challenge in the bad old days was that every single one of your customers probably had a different version of your system, and was both demanding in fixing their bugs, but refusing to upgrade to your latest release. Therefore you had to manage lots of patch branches.
The challenge in the bad old days was that every single one of your customers probably had a different version of your system, and was both demanding in fixing their bugs, but refusing to upgrade to your latest release. Therefore you had to manage lots of patch branches.git log <old>..<new>In the software as a service model, you don't have the patching problem. Instead, you have the challenge of getting your fixes out to production as fast and as safely as possible.
 The mantra here is: if it ain't broke, don't fix it. As we've seen before, rebuilding and re-releasing an unchanged component already can have risks, and forcing a working component to be rebuilt because of unrelated changes will at least cause delay.
The mantra here is: if it ain't broke, don't fix it. As we've seen before, rebuilding and re-releasing an unchanged component already can have risks, and forcing a working component to be rebuilt because of unrelated changes will at least cause delay.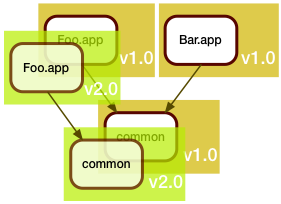 In this example, Foo.app got updated. This update unfortunately also required a fix to the shared code library. Arguably, Bar.app should be rebuilt to see if the fix broke it, but we are in a hurry (when are we ever not in a hurry?), and since Bar.app is functioning fine as is, we don't rebuild it. We just leave it alone.
In this example, Foo.app got updated. This update unfortunately also required a fix to the shared code library. Arguably, Bar.app should be rebuilt to see if the fix broke it, but we are in a hurry (when are we ever not in a hurry?), and since Bar.app is functioning fine as is, we don't rebuild it. We just leave it alone.Bar.app: unchangedIn order to divine this somehow, we need to register the exact revisions used for every piece of the build. I personally like build manifests embedded someplace in the deliverable items. These build manifests would include all the dependency information, and would look somewhat like this:
Foo.app: git log v1.0..v2.0 # in Foo.app's repo
git log v1.0..v2.0 # in common's repo
{ "Name": "Foo.app",The same idea can be used to describe the state of a complete release. We just aggregate all the build manifests into a larger one:
"Rev": "v2.0",
"Includes": [ { "Name": "common",
"Rev": "v2.0" } ] }
{ "Name": "January Release",
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v1.0" }]}]}
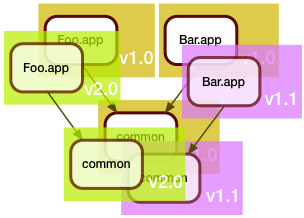 Now the development team around Bar.app wasn't idle during all this time, and they also came up with some changes. They too needed to update the shared code in common.
Now the development team around Bar.app wasn't idle during all this time, and they also came up with some changes. They too needed to update the shared code in common.{ "Name": "February Release",It should be easy to see how recursive traversal of both build manifests will yield the answer to the question "What changed between January and February?":
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.1",
"Includes": [{ "Name": "common",
"Rev": "v1.1" }]}]}
Foo.app: unchanged
Bar.app: git log v1.0..v1.1 # in Bar.app's repo
git log v1.0..v1.1 # in common's repo
 So far, this wasn't so difficult. Where things get interesting is when a brand new service comes into play.
So far, this wasn't so difficult. Where things get interesting is when a brand new service comes into play.{ "Name": "March Release",So, what changed between February and March?
"Includes: [{ "Name": "Foo.app",
"Rev": "v2.0",
"Includes": [{ "Name": "common",
"Rev": "v2.0" }]},
{ "Name": "Bar.app",
"Rev": "v1.1",
"Includes": [{ "Name": "common",
"Rev": "v1.1" }]},
{ "Name": "New.app",
"Rev": "v1.0",
"Includes": [{ "Name": "common",
"Rev": "v2.1" }]}]}
Foo.app: unchangedThe first part of the answer is easy. Since New.app's repository is brand new, it only makes sense to include all changes.
Bar.app: unchanged
New.app: ????
Foo.app: unchangedOne can make a reasonable argument that from the point of view of New.app, all the changes in common are also new, so they should be listed. In practice, though, this could be a huge list, and wouldn't really be that useful, as most changes would be completely unrelated to New.app, and also would be unrelated to anything within the new release. We need something better.
Bar.app: unchanged
New.app: git log v1.0 # in New.app's repository
and then ????
Foo.app: unchangedBut how do we code this?
Bar.app: unchanged
New.app: git log v1.0 # in New.app
git log v2.1 ^v2.0 ^v1.1 # in common
<prefix>-<YYYY-MM-DD>-<top-level-name>-<version>[+<dependency-path>]
On Re-tagging
What should you do when you tag a wrong commit and you
would want to re-tag?
If you never pushed anything out, just re-tag it.
Use "-f" to replace the old one. And you're done.
But if you have pushed things out (or others could
just read your repository directly), then others will
have already seen the old tag. In that case you can
do one of two things:
1. The sane thing. Just admit you screwed up, and
use a different name. Others have already seen
one tag-name, and if you keep the same name,
you may be in the situation that two people both
have "version X", but they actually have different
"X"'s. So just call it "X.1" and be done with it.
2. The insane thing. You really want to call the new
version "X" too, even though others have already seen
the old one. So just use git tag -f again, as if you
hadn't already published the old one.
However, Git does not (and it should not) change tags behind
users back. So if somebody already got the old tag, doing a
git pull on your tree shouldn't just make them overwrite the
old one.
If somebody got a release tag from you, you cannot just change
the tag for them by updating your own one. This is a big
security issue, in that people MUST be able to trust their tag
names. If you really want to do the insane thing, you need
to just fess up to it, and tell people that you messed up.
You can do that by making a very public announcement saying:
Ok, I messed up, and I pushed out an earlier version
tagged as X. I then fixed something, and retagged the
*fixed* tree as X again.
If you got the wrong tag, and want the new one, please
delete the old one and fetch the new one by doing:
git tag -d X
git fetch origin tag X
to get my updated tag.
You can test which tag you have by doing
git rev-parse X
which should return 0123456789abcdef..
if you have the new version.
Sorry for the inconvenience.
Does this seem a bit complicated? It should be. There is no way
that it would be correct to just "fix" it automatically. People
need to know that their tags might have been changed.

{kind=link}